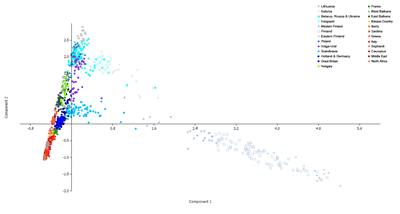
The Principal Component Analyses (PCA) below are based on pairwise Identity-by-Descent (IBD) sharing inferred with fastIBD. My aim was to create PCA that took into account haplotype information to see how they might differ from similar plots based on unlinked loci (such as here).




Clearly, they're less reflective of geography and isolation-by-distance, and instead more profoundly influenced by relatively recent isolation, founder effects and/or rapid expansions, especially in Northern and Eastern Europe, and in particular among the Finns, Balts and East Slavs. Unfortunately, I don't have time to say much more about these results. But feel free to post any questions or observations in the comments below. I have done something very similar in the past, but with far fewer samples (see here).
Please note, to ensure that the PCA were as informative as possible I was forced to drop several populations that produced unusual results, probably because of extreme founder effects. This is why, for instance, there are no Ashkenazi Jews on any of the plots, and the only Finns you'll find come from western Finland.
I'll try this again on a much larger dataset when more samples come in, and also include populations from Central and South Asia.
Update 7/8/2014: Apparently some people are wondering what the plots with Finns and Jews look like. Here you go...
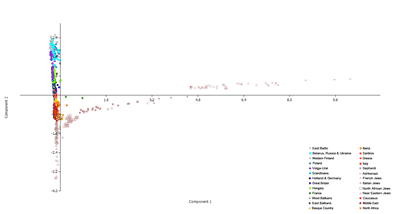
23 comments:
David, you may be interested http://verenich.wordpress.com/2014/07/26/%D0%B2%D0%B8%D0%B7%D1%83%D0%B0%D0%BB%D0%B8%D0%B7%D0%B0%D1%86%D0%B8%D1%8F-%D0%BA%D0%BE%D0%BB%D0%B8%D1%87%D0%B5%D1%81%D1%82%D0%B2%D0%B0-%D0%BE%D0%B1%D1%89%D0%B8%D1%85-ibd-%D1%81%D0%B5%D0%B3%D0%BC/
On the first PCA, I noticed that Greece spreads between Italy and the East Balkans.
West Balkans is more extreme towards Belarus/Russia/Ukraine and Poland. It looks like the Slavic languages came down like a wedge into West Balkans.
Interesting hints about migration path. Again hinted by deep R1a haplotype diversity in Kashubs and Sorbs. Are they preserving the Proto-Slav source population base in some way?
Everybody got squished on the PCA with eastern finns. How come?
Groups showing low levels of cM sharing always get squished by those showing excessive levels of cM sharing.
It happened to the Near Eastern samples on the West Eurasian PCA. So in order to flesh out detail within the Near East, I'd have to remove the Northeastern Europeans and Scandinavians, and probably a few other groups as well.
Is there anything like a pc4? Using La Brana, Malta, mbuti, and Dai, maybe.
Nice work. Could you post some PCA with individual Eurogenes IDs?
It's unlikely that you're on those PCA, but what's your ID?
Davidsk which PCA plot should be most precise/accurate of the first four?
I think some of my family might be in this run: SE36, FI16 and FSE1?
Random ten samples from a country with 80 million people show less shared IBD-segments than from a populatio with 1.5 million people. I am not saying that the population structure has no effect on the results, but that the fundaments of usually seen PCAs are not adequate.
@ David
Is it the same method that you used to differentiate IBD from IBS at Eurogenes detective ?
I don't know if Iam in these PCAs, but if that's the case I ( FR20) am probably located with the British and not the French, being shifted East.
Tesmos,
All of these plots are accurate, but each one shows different things. So when you look at each plot have a think about what the components represent based on the samples that are featured. For instance, on the first plot dimension one is probably focusing on Near Eastern versus Northeast European ancestry. On the other hand, dimension one on the second plot seems to reflect Southern European versus Fennoscandian ancestry.
geneoholic, Helgenes50 and Fanty,
You're not on these plots, but I do have you all on very similar plots. I'll post the datasheets for those later today.
David,
Am I or will I be on any of these plots?
You'll be on the datasheets that I'll post later today. You'll have to run these with something like Past3 or Gnuplot.
Hah, I was curious whether I was one of the green dots away from the French core on the plot with Jewish populations.
Otherwise, I find it quite impressive how much the PCAs end up looking like IBS PCAs, what's the minimum segment length recognised as IBD for these.
Also, I wouldn't mind having a look at the distance matrixes, I feel like they could be interesting too.
Thank you David.
Would someone be able to run my results from the spreadsheets once David releases them please? My Eurogenes id is CA1. I do not know how to do this on my computer. You can send my results to this email. jackson_montgomery_devoni@hotmail.com
If someone could do this I would greatly appreciate it.
Here are those datasheets. They should produce plots very similar to those above (West Eurasian, European and Finnish). I tried to include as many regular and not so regular contacts as possible. Apologies if I missed anyone out.
https://drive.google.com/file/d/0B9o3EYTdM8lQa1ZacUxwTFZpYm8/edit?usp=sharing
You can run them with gnuplot. To get a 2D plot based on the first two components, try:
plot 'PCA1.txt' using 2:3:1 with labels
To use dimensions 1&3, try:
plot 'PCA1.txt' using 2:4:1 with labels
To get a 3D plot based on the the first three dimensions, try:
splot 'PCA1.txt' using 2:3:4:1 with labels
Gui,
You might find this pairwise cM matrix interesting. It's in Past3 format, but can be opened with any spreadsheet software.
https://drive.google.com/file/d/0B9o3EYTdM8lQTXUwU0F2OFUzS2c/edit?usp=sharing
It actually features West Eurasian and South Central Asian samples, so it might be useful for looking at gene flow between Western Europe and South Central Asia.
Again, I tried to include as many project people as possible, but not everyone is listed.
Now that the new spreadsheets are out would someone be able to please run my results for me? My Eurogenes id is CA1. I would appreciate it greatly if someone could. You can send my results to my email listed here. :)
Hi David, interesting post. I wonder wether it is possible to share your code to create PCs based on IBD sharing inferred with BEAGLE fastIBD.
Thanks!
You need to first make sure that the output looks exactly like this in a fastIBD.txt file, with each segment shared by pairs of samples expressed as a cM score. I can't explain here how to do that. I'd need to write up a tutorial.
Ecuadorian_GSM531168 Yoruban_HGDP00943 0.6925
Bantu_S.E._HGDP01034 Mbuti_Pygmy_HGDP00450 5.7598
Biaka_Pygmy_HGDP00458 Biaka_Pygmy_HGDP00464 4.8604
Mandenka_HGDP00908 Sudanese_Sudanese2b 2.7769
Mandenka_HGDP00908 Yoruban_NA18487 6.2823
Luhya_NA19031 Mbuti_Pygmy_HGDP00478 5.8433
But if you can do it, then all you need to do then is to run this script in R, assuming that you have the bdsmatrix package installed. And then once you have a matrix of IBD sharing in a text file, you just use something like Past3 PCA software to plot the results.
library(bdsmatrix)
forag <- read.table("fastIBD.txt", sep="\t")
Blah <- aggregate(V3 ~ V1 + V2, data = forag, sum)
asm1 <- as.matrix(Blah$V1)
asm2 <- as.matrix(Blah$V2)
str <- append(asm1, asm2)
df <- data.frame(str)
num <- data.matrix(df)
unum <- unique(num)
ustr <- unique(str)
unum <- sort(unum)
ustr <- sort (ustr)
idmap <- data.frame(unum,ustr)
c1 <- num[1:(nrow(num)/2),]
c2 <- num[((nrow(num))/2+1):nrow(num),]
c3 <- Blah$V3
numMat <- data.frame(c1, c2, c3)
bdsMat <- bdsmatrix.ibd(numMat$c1, numMat$c2, numMat$c3, idmap, 1)
final <- as.matrix(bdsMat)
write.table(final, "final.txt", sep="\t")
About Time
They can not "came down" by the simple reason as the earliest mentioned Slavonia region is in the Balkans/Danube region/. The Russians were called slavs about 1000 years after the name Slavs / Sclaveni was registered in the lands of the Gets.
Post a Comment