Most visitors here are probably aware by now that the Iron Age genomes from Hinxton are the two male samples 1 and 4 (ERS389795 and ERS389798, respectively). You can find confirmation of this at the link below.
The researchers were surprised to find that the older Iron Age men were genetically more similar to people living in Britain today than the Anglo-Saxon women were. Stephan Schiffels of the Wellcome Trust Sanger Institute reported the results October 20 at the annual meeting of the American Society of Human Genetics.
“It doesn’t look like these Anglo-Saxon immigrants left a big impact on the genetic makeup of modern-day Britain,” Schiffels said.
The finding raises an intriguing possibility that indigenous people in Britain may have repelled the Anglo-Saxons but adopted the invaders’ language and culture, says Eimear Kenny, a population geneticist at the Icahn School of Medicine at Mount Sinai in New York City, who was not involved in the work. More ancient samples from other times and parts of Britain should give a clearer picture of that episode of history, she said.
Anglo-Saxons left language, but maybe not genes to modern Britons
In regards to the main thrust of the article above, I'm not sure if there's much point discussing whether the British today are mostly of Celtic or Anglo-Saxon stock based on just five ancient genomes from a single location in England. However, if I was told that Hinxton4, the only high coverage genome in this collection, was a modern sample, I'd say it belonged to an Irishman from western Ireland, rather than an Englishman from eastern England.
Thus, unless Hinxton4 was an ancient migrant from Ireland, then it does seem to me as if there was a fairly significant admixture event in England between the indigenous Irish-like Celts and newcomers from the east, which eventually resulted in the present-day English population.
In any case, there are indeed some noticeable differences between the two sets of samples, and these can be visualized by plotting their f3 shared drift statistics.
For instance, plotting the f3-statistics of Hinxton2, which actually looks like the genome of someone straight off the boat from the Jutland Peninsula, against those of Hinxtons 1 and 4, we see that the former shares most drift with the Danes. Moreover, the Danes, Swedes and Germans, all Germanic speakers of course, deviate strongly on both graphs from the lines of slope that run from the Erzya to the Irish. The reason they deviate from these lines is because they don't share enough drift with Hinxtons 1 and 4 compared to the other reference populations from Northwestern Europe, especially the Irish.
A similar pattern can be seen when plotting the average results of Hinxtons 1 and 4 against those of 2, 3 and 5. However, the effect isn't nearly as pronounced, possibly because Hinxtons 3 and 5 are of mixed Celtic/Germanic origin.
See also...
Analysis of an ancient genome from Hinxton
Analysis of Hinxton2 - ERS389796
Analysis of Hinxton3 - ERS389797
Analysis of Hinxton4 - ERS389798
Analysis of Hinxton5 - ERS389799
Hinxton5, or ERS389799, is one of five ancient English genomes stored at the Sequence Read Archive under accession number ERP003900. However, this analysis is based on the genotype file of Hinxton5 available at Genetic Genealogy Tools. For more information and some speculation about these genomes see my earlier blog post here.
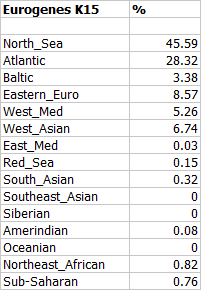
Despite its relatively low North Sea score in the Eurogenes K15, and pronounced western shift on the Principal Component Analysis (PCA) plots, this genome appears mostly Germanic. In my opinion, the shared drift stats and also oracle results are quite convincing in this regard. If this were a modern sample it could probably pass for 3/4 north Dutch and 1/4 Irish. By the way, the Sub-Saharan admixture just looks like noise; this is, after all, a low coverage genome.
Shared drift stats of the form f3(Mbuti;Hinxton5,Test) - Eurogenes dataset
Shared drift stats of the form f3(Mbuti;Hinxton5,Test) - Human Origins dataset
Eurogenes K15 4 Ancestors Oracle results
See also...
Analysis of Hinxton2 - ERS389796
Analysis of Hinxton3 - ERS389797
Analysis of Hinxton4 - ERS389798
Hinxton ancient genomes roundup
Not long ago I predicted that Ust'-Ishim belonged to a basal form of Y-chromosome haplogroup P (see here). As it turns out, the 45,000 year-old western Siberian genome belongs to K(xLT) or K-M526, which is actually pretty close to my guess. The Ust'-Ishim paper was published today and is sitting behind a paywall here, but the extensive supp info is free.
Here's a map to help visualize the information, featuring Ust'-Ishim as well as Mal'ta boy, another North Eurasian Upper Paleolithic genome published recently.
The Ust'-Ishim genome was sequenced from the fossil of a femur bone found on the right bank of the Irtysh River. This area is very close to the Urals, and almost in the middle of the former Mammoth steppe that once stretched across North Eurasia from Iberia to Alaska. Interestingly, M526 is an ancestral mutation to the markers that define Y-chromosome haplogroups N, Q and R, which possibly dominated North Eurasia since the Upper Paleolithic (note that the 24,000 year-old Mal'ta boy belongs to a basal form of R).
Moreover, R1a and R1b are the most frequent haplogroups in Europe today. Thus, it would seem that most European males derive their paternal ancestry from North Eurasian hunter-gatherers whose ancestors spread out across Eurasia from the Middle East over 45,000 years ago.
I know that a lot of people have been arguing recently that K-M526 and the derived P-M45 originated and diversified in Southeast Asia, and then migrated north well within the last 45,000 years (for instance, see here). However, considering that K-M526 was already in reindeer country 45,000 years ago, as well as the Denisovan (ancient Siberian hominin) admixture among Southeast Asians, that might well turn out to be the equivalent of arguing that up is down and down is up.
By the way, Ust'-Ishim also belongs to pan-Eurasian mitochondrial (mtDNA) haplogroup R*, and in terms of genome-wide genetic structure appears roughly intermediate between West and East Eurasians. These outcomes fit very nicely with its Y-haplogroup.
However, it's slightly closer to Mesolithic Iberian genome La Brana-1, Upper Paleolithic Siberian MA-1 (or Mal'ta boy), and present-day East Asians, than to present-day West Eurasians, including Europeans. That's because it lacks "ancestry from a population that did not participate in the initial dispersals of modern humans into Europe and Asia". This is obviously the so called Basal Eurasian admixture discussed in Lazaridis et al. (see here), which is probably associated with early Neolithic farmers.
Also worth mentioning is that Ust'-Ishim harbors longer stretches of Neanderthal chromosomal segments than present-day Eurasians, which suggests that admixture between modern humans and Neanderthals took place in the Middle East not long before the ancestors of Ust-Ishim moved into Siberia (50-60,000 years ago). But this was already covered months ago, and you'll find lots of links on the topic on Google.
Citation...
Qiaomei Fu et al., Genome sequence of a 45,000-year-old modern human from western Siberia, Nature 514, 445–449 (23 October 2014) doi:10.1038/nature13810
See also...
Y-haplogroup P1 in Pleistocene Siberia (Sikora et al. 2018 preprint)
Hinxton4, or ERS389798, is one of five ancient English genomes stored at the Sequence Read Archive under accession number ERP003900. However, this analysis is based on the genotype file of Hinxton4 available at Genetic Genealogy Tools. For more information and some speculation about these genomes see my earlier blog post here.
I still don't know who these samples represent exactly, but in all likelihood, this is one of the two Iron Age sequences from the collection, and probably belongs to a Briton of Celtic stock. Note, for instance, its high affinity to the present-day Irish, relatively low North Sea score in the Eurogenes K15, and pronounced western shift on the second Principal Component Analysis (PCA) plot below.
Interestingly, Lithuanians top its shared drift list based on the Human Origins dataset and more than 360K SNPs. I'm not entirely sure what this means, but it's probably related in some way to the unusually high level (>45%) of indigenous European hunter-gatherer ancestry carried by Lithuanians.
Shared drift stats of the form f3(Mbuti;Hinxton4,Test) - Eurogenes dataset
Shared drift stats of the form f3(Mbuti;Hinxton4,Test) - Human Origins dataset
Eurogenes K15 4 Ancestors Oracle results
See also...
Analysis of Hinxton2 - ERS389796
Analysis of Hinxton3 - ERS389797
Analysis of Hinxton5 - ERS389799
Hinxton ancient genomes roundup
Hinxton3, or ERS389797, is one of five ancient English genomes stored at the Sequence Read Archive under accession number ERP003900. However, this analysis is based on the genotype file of Hinxton3 available at Genetic Genealogy Tools. For more information and some speculation about these genomes see my earlier blog post here.
Despite the exaggerated North Sea score in the Eurogenes K15, Hinxton3 could easily pass for a present-day Briton from the eastern coast of England or Scotland, albeit with a stronger than usual pull towards Scandinavia. Indeed, the f3-statistics show that it shares most genetic drift with the British and Icelanders from Eurogenes and Human Origins, respectively.
Shared drift stats of the form f3(Mbuti;Hinxton3,Test) - Eurogenes dataset
Shared drift stats of the form f3(Mbuti;Hinxton3,Test) - Human Origins dataset
Eurogenes K15 4 Ancestors Oracle results
See also...
Analysis of Hinxton2 - ERS389796
Analysis of Hinxton4 - ERS389798
Analysis of Hinxton5 - ERS389799
Hinxton ancient genomes roundup
Hinxton2, or ERS389796, is one of five ancient English genomes stored at the Sequence Read Archive under accession number ERP003900. However, this analysis is based on the genotype file of Hinxton2 available at Genetic Genealogy Tools. For more information and some speculation about these genomes see my earlier blog post here.
Interestingly, f3-statistics in the form f3(Mbuti;Hinxton2,Test) show that Hinxton2 shares most genetic drift with present-day Danes and Norwegians. Please refer to the relevant spreadsheets below.
Shared drift stats of the form f3(Mbuti;Hinxton2,Test) - Eurogenes dataset
Shared drift stats of the form f3(Mbuti;Hinxton2,Test) - Human Origins dataset
Eurogenes K15 4 Ancestors Oracle results
See also...
Analysis of Hinxton3 - ERS389797
Analysis of Hinxton4 - ERS389798
Analysis of Hinxton5 - ERS389799
Hinxton ancient genomes roundup
Several ancient genomes have been posted online as text files and uploaded to GEDmatch over the last couple of weeks, and many more are likely to follow in the future. A lot of people have already taken this opportunity to analyze these files with various online ancestry tools, usually DIY calculators.
That's actually not a bad way of doing things, as long as everyone's aware that almost all of these calculators produce biased results. They produce biased results because they violate a very basic rule of science, which is this:
Do not test more than one variable at a time.
Obviously, the variable we want to test with these calculators is ancestry. However, when the reference samples are tested in a different way to the test samples, which is what usually happens, then this adds another variable to the proceedings. As a result, we simply can't compare the results of the reference samples to those of the test samples.
I know that a lot of people find this difficult to grasp, and many just seem hell bent on not grasping it. However, anyone who isn't completely insane, and takes five minutes out of their day to try and understand the concepts involved, has to agree that this is a real problem. It can be proven empirically, like I did over two years ago (see here).
I suspect that a lot of confusion has been caused by the fact that the people who were used as reference samples in the making of the various DIY calculators saw highly accurate results when running them, and so assumed everything was fine. The accuracy of the DIY calculators for such people is indeed impressive, and I show that at the link above, but unfortunately the story is very different for everyone else.
Here's the good news: the Eurogenes calculators don't suffer from the calculator effect. That's because the reference samples are treated in the same way as the test samples, so there's only one variable: ancestry. What this means is that when you run a modern or ancient genome with a Eurogenes calculator you can confidently compare the result to those of the reference samples (provided enough SNPs are used), and then be able to make sensible inferences about its genetic origins.
I've just added an ancient sample from Hinxton, England, to my burgeoning ancient genomes collection. It's a pre-publication release freely available here as ERS389795. Thanks to Felix C. for breaking the news. We've both called this sample Hinxton1.
Unfortunately, its archeological context is a mystery to me, but it's possibly one of the ancient genomes mentioned in the recent Schiffels et al. ASHG abstract (see here).
In terms of genome-wide genetic structure, Hinxton1 is most similar to present-day Orcadians, Irish, western Scots, Icelanders and western Norwegians, more or less in that order. However, it's fairly distinct from the modern inhabitants of England, or at least those in my datasets, who mostly come from Kent and Cornwall.
Please note, this analysis features two different datasets: Eurogenes and Human Origins. Eurogenes, which is my own dataset, includes more populations than Human Origins, and is based on SNPs used in commercial ancestry and medical work. On the other hand, Human Origins shows a more varied sampling strategy, and is based on SNPs specifically chosen for population genetics.
Shared drift stats in the form f3(Mbuti;Hinxton1,Test) - Eurogenes dataset
Shared drift stats in the form f3(Mbuti;Hinxton1,Test) - Human Origins dataset
Eurogenes K15 4 Ancestors Oracle results
See also...
Analysis of Hinxton2 - ERS389796
Analysis of Hinxton3 - ERS389797
Analysis of Hinxton4 - ERS389798
Analysis of Hinxton5 - ERS389799
Hinxton ancient genomes roundup