Not long ago Lazaridis et al. proposed that most present-day Europeans were derived from three distinct ancestral populations: Ancient North Eurasians (ANE), Early European Farmers (EEF) and Western European Hunter-Gatherers (WHG).
However, this is essentially a stop-gap model, which will in all likelihood be replaced by a partly revised and more robust model once someone manages to sequence a genome or two from the Neolithic Near East. That's because EEF is clearly a hybrid component, largely made up of ancient Near Eastern ancestry and something very WHG-like, sometimes in very different proportions depending on the location and archeological context of the EEF genomes being analyzed.
So what will this new model look like, you might ask? Probably like this, where EEF is replaced by an Early Neolithic Farmer (ENF) component from the ancient Near East, or something very similar:
The diagram above is basically a Principal Component Analysis (PCA) based on output from my new West Eurasia K8 test (see here), in which the Near Eastern component is synonymous with ENF.
I'm quite certain that these results are very close to the truth. However, just in case the Near Eastern ancestry proportions are a little bit too high (and we won't know until we see those ancient genomes from the Near East), I've got another version that offers lower bound Near Eastern estimates.
It might be useful to keep in mind that I rotated the plots to fit geography. As a result, Component 1, which packs around 85% of the variance on both plots, appears smaller than Component 2, which only carries around 10% of the variance.
A spreadsheet with West Eurasia K8 results for a wide variety of populations is available here. Please note that there are two sheets, with the second sheet showing the lower bound Near Eastern ancestry proportions.
We'll probably learn of more ancient European meta-populations as many more genomes are sequenced from across Eurasia. Nevertheless, I doubt this will affect the model outlined above. That's because I'm expecting all such meta-populations to be mixtures of ANE, ENF and/or WHG, as well as, in some cases, extra-West Eurasian components.
However, I suspect that West Eurasia will have to be modeled in a different way from Europe, with, amongst other things, the so called Basal Eurasian component replacing ENF. But for this to happen we'll need at least one ancient genome that is in large-part of Basal Eurasian origin. In any case, that's a whole different subject.
See also...
4mix: four-way mixture modeling in R
I've seen quite a few comments on this blog suggesting that most of the Ancient North Eurasian (ANE) admixture found in Northern Europe today might come from Scandinavian hunter-gatherers like Motala12 and Ajvide58. It's probably obvious to most that this is not realistic, because the Scandinavian forager genomes sequenced to date show very high ratios of Western European Hunter-Gatherer (WHG) ancestry (>80%), so basically the math doesn't add up.
Nevertheless, I thought it might be useful to drive the point home using this Principal Component Analysis (PCA) based on my new West Eurasia K8 test. The datasheet is available here. You can view a spreadsheet of the results with extra samples here.
Please note that neither Motala12 nor Gokhem2, a late Neolithic farmer from south Sweden belonging to the Funnelbeaker culture, can pass for present-day Swedes. Moreover, mixing Gokhem2 with Motala12, in any proportions, will not produce a result even vaguely similar to present-day Swedes (ie. the outcome will fall somewhere along the dotted line).
I'd say one of the most obvious ways to get the right result would be to blend the Scandinavian forager and farmer with at least one other sample from somewhere below (ie. geographically speaking, east or southeast) of the Swedish cluster.
It might be possible to come up with a more precise plot location, and thus perhaps geographic origin, for this putative third source of Swedish ancestry by running some complex tests with the PCA datasheet. If anyone wants to have a go at that, and you actually manage to come up with a coherent outcome, then feel free to post your findings in the comments below.
I've decided not to bother, because as far as I can see, the options are infinite. What we really need are more genomes from the Swedish late Neolithic/early Bronze Age (LN/EBA), preferably belonging to one of the local spin-offs of the Corded Ware culture, which is thought to have originated in Eastern Europe, to provide more datapoints and help narrow down the options.
On a related note, I'm catching up on some reading this holiday season, and currently going through this book chapter which discusses the upheavals during the LN/EBA in south Scandinavia as seen through its archeology.
Rune Iversen, Beyond the Neolithic transition - the "de-Neolithisation" of south Scandinavia
See also...
Bell Beaker, Corded Ware, EHG and Yamnaya genomes in the fateful triangle
Here's a Principal Component Analysis (PCA) and an accompanying biplot based on output from an improved version of my ANE K7 ancestry test. Let's call it the West Eurasia K8. This one gives more accurate estimates of Western European Hunter-Gatherer (WHG) and Near Eastern admixture proportions, thanks to the use of new ancient samples.
When rotated accordingly (like here), the results are basically indistinguishable from those I get with genotype data (for instance, see here and here), which suggests that they're correct and based on ancestry proportions that are close to the truth. The Past3 data sheet used to create the PCA is available here. You can view a spreadsheet of the results with extra samples here.
Clearly, ANE is the main agent causing the west to east differentiation in dimension 2. Note that even a small rise in ANE, say, 4-5%, creates significant distance between samples on the PCA plot.
East and South Eurasian admixture has a similar effect, but must be more considerable to make an impact on a West Eurasian-specific PCA like this (and it does with the obvious Volga-Ural outliers, who come from Chuvashia and Tatarstan).
On the other hand, Near Eastern admixture without ANE creates almost the opposite effect. Note, for instance, that Neolithic genomes Stuttgart and NE1 show much higher levels of Near Eastern ancestry than most Europeans, and yet they're amongst the most western samples on the plot.
This suggests that the Near East, and in particular the Caucasus, experienced a significant rush of ANE admixture after early Neolithic farmers left the region for Europe. Alternatively, Caucasus populations may have carried even higher levels of ANE than they do today, before newcomers from the Near East mixed with them. But either way, a lot of ANE arrived in the Near East at some point.
It also suggests that, overall, the populations that moved west across northern Europe after the Neolithic, and shifted northern European genetic structure to the east, did not carry high ratios of Near Eastern ancestry. Instead, they harbored high ratios of ANE and WHG. What these ratios were exactly I haven't a clue, but ancient DNA should tell us that soon.
Below are the ancestry proportions for the five ancient genomes in this analysis, in chronological order. It's interesting to note (yet again) the rising and falling Near Eastern admixture, from the Mesolithic to Neolithic and then from the Neolithic to Bronze Age, respectively, as well as the steady rise of ANE from the Bronze Age to the Iron Age.
Loschbour (Mesolithic)
ANE 0
South_Eurasian 0
Near_Eastern 0
East_Eurasian 0
WHG 99.5
Oceanian 0.5
Pygmy 0
Sub-Saharan 0
Stuttgart (Neolithic)
ANE 0
South_Eurasian 0
Near_Eastern 72.19
East_Eurasian 0
WHG 27.8
Oceanian 0
Pygmy 0
Sub-Saharan 0
NE1 (Neolithic)
ANE 0
South_Eurasian 0
Near_Eastern 69.82
East_Eurasian 0
WHG 30.17
Oceanian 0
Pygmy 0
Sub-Saharan 0
BR2 (Bronze Age)
ANE 9.62
South_Eurasian 0.08
Near_Eastern 43.96
East_Eurasian 0
WHG 45.44
Oceanian 0.48
Pygmy 0.23
Sub-Saharan 0.19
Hinxton4 (Iron Age)
ANE 15.08
South_Eurasian 0.06
Near_Eastern 35.44
East_Eurasian 0.46
WHG 48.5
Oceanian 0
Pygmy 0
Sub-Saharan 0.46
See also...
The fateful triangle
Bell Beaker, Corded Ware, EHG and Yamnaya genomes in the fateful triangle
The map below is based on data from Warinner et al. 2014. It shows the consumption of milk, or lack of, among Late Neolithic/Bronze Age (LN/BA) individuals from across West Eurasia. Admittedly, the sampling is very sparse, but like I've said before on these blogs, the LN/BA was a time of profound changes in Europe, so every scrap of data from this period is very valuable.
Note the lack of milk consumption among the samples from north of the Alps, where today the vast majority of people consume milk as adults, and can do so because they carry the Lactase Persistence Allele (T-13910). This doesn't look like a coincidence, considering the mounting evidence of a major population turnover across much of Europe during the LN/BA, mostly as a result of migrations from the east.
Citation...
Warinner, C. et al. Direct evidence of milk consumption from ancient human dental calculus. Sci. Rep. 4, 7104; DOI:10.1038/srep07104 (2014).
See also...
Lactase persistence and ancient DNA
Ancient genomes from the Great Hungarian Plain
Update 20/05/2015: Large-scale recent expansion of European patrilineages
...
I wonder what the hardcore Y-DNA genetic genealogists will say about this effort? I know that many of those guys have been working with full Y-chromosome sequences for a while now. It's open access with lots of supplementary info.
Abstract: Many studies of human populations have used the male-specific region of the Y chromosome (MSY) as a marker, but MSY sequence variants have traditionally been subject to ascertainment bias. Also, dating of haplogroups has relied on Y-specific short tandem repeats (STRs), involving problems of mutation rate choice, and possible long-term mutation saturation. Next-generation sequencing can ascertain single nucleotide polymorphisms (SNPs) in an unbiased way, leading to phylogenies in which branch-lengths are proportional to time, and allowing the times-to-most-recent-common-ancestor (TMRCAs) of nodes to be estimated directly. Here we describe the sequencing of 3.7 Mb of MSY in each of 448 human males at a mean coverage of 51x, yielding 13,261 high-confidence SNPs, 65.9% of which are previously unreported. The resulting phylogeny covers the majority of the known clades, provides date estimates of nodes, and constitutes a robust evolutionary framework for analysing the history of other classes of mutation. Different clades within the tree show subtle but significant differences in branch lengths to the root. We also apply a set of 23 Y-STRs to the same samples, allowing SNP- and STR-based diversity and TMRCA estimates to be systematically compared. Ongoing purifying selection is suggested by our analysis of the phylogenetic distribution of non-synonymous variants in 15 MSY single-copy genes.
Here are a couple of interesting quotes. You can see the samples they're talking about on the tree below. As per the second paragraph, it seems there's a paper about to be published at Nature Communications on European Y-chromosome haplogroups based on some heavy resequencing data (see Batini et al. in the references list). Can't wait for that.
(viii) Rare deep-rooting hg Q lineages in NW Europe: Hg Q has been most widely investigated in terms of the peopling of the Americas from NE Asia (Karafet et al. 1999). Here, as well as an example of the common native American Q-M3 lineage, we included examples of rare European hg Q chromosomes. One of the English chromosomes belongs to the deepest-rooting lineage within Q (Q-M378) and may reflect the Jewish diaspora (Hammer et al. 2009); the other is distantly related, shares a deep node with the Mexican Q-M3 chromosome, and has an STR-haplotype closely related to those of scarce Scandinavian hg Q chromosomes (unpublished data).
(ix) Structure within the west Eurasian hg R: The TMRCA of hg R is 19 KYA, and within it both hgs R1a and R1b comprise young, star-like expansions discussed extensively elsewhere (Batini et al. submitted). The addition of Central Asian chromosomes here contributes a sequence to the deepest subclade of R1b-M269, while another, in a Bhutanese individual, forms an outgroup almost as old as the R1a/R1b split.

Citation...
Hallast et al., The Y-chromosome tree bursts into leaf: 13,000 high-confidence SNPs covering the majority of known clades, Molecular Biology & Evolution, published online December 2, 2014, doi: 10.1093/molbev/msu327
Most visitors here are probably aware by now that the Iron Age genomes from Hinxton are the two male samples 1 and 4 (ERS389795 and ERS389798, respectively). You can find confirmation of this at the link below.
The researchers were surprised to find that the older Iron Age men were genetically more similar to people living in Britain today than the Anglo-Saxon women were. Stephan Schiffels of the Wellcome Trust Sanger Institute reported the results October 20 at the annual meeting of the American Society of Human Genetics.
“It doesn’t look like these Anglo-Saxon immigrants left a big impact on the genetic makeup of modern-day Britain,” Schiffels said.
The finding raises an intriguing possibility that indigenous people in Britain may have repelled the Anglo-Saxons but adopted the invaders’ language and culture, says Eimear Kenny, a population geneticist at the Icahn School of Medicine at Mount Sinai in New York City, who was not involved in the work. More ancient samples from other times and parts of Britain should give a clearer picture of that episode of history, she said.
Anglo-Saxons left language, but maybe not genes to modern Britons
In regards to the main thrust of the article above, I'm not sure if there's much point discussing whether the British today are mostly of Celtic or Anglo-Saxon stock based on just five ancient genomes from a single location in England. However, if I was told that Hinxton4, the only high coverage genome in this collection, was a modern sample, I'd say it belonged to an Irishman from western Ireland, rather than an Englishman from eastern England.
Thus, unless Hinxton4 was an ancient migrant from Ireland, then it does seem to me as if there was a fairly significant admixture event in England between the indigenous Irish-like Celts and newcomers from the east, which eventually resulted in the present-day English population.
In any case, there are indeed some noticeable differences between the two sets of samples, and these can be visualized by plotting their f3 shared drift statistics.
For instance, plotting the f3-statistics of Hinxton2, which actually looks like the genome of someone straight off the boat from the Jutland Peninsula, against those of Hinxtons 1 and 4, we see that the former shares most drift with the Danes. Moreover, the Danes, Swedes and Germans, all Germanic speakers of course, deviate strongly on both graphs from the lines of slope that run from the Erzya to the Irish. The reason they deviate from these lines is because they don't share enough drift with Hinxtons 1 and 4 compared to the other reference populations from Northwestern Europe, especially the Irish.
A similar pattern can be seen when plotting the average results of Hinxtons 1 and 4 against those of 2, 3 and 5. However, the effect isn't nearly as pronounced, possibly because Hinxtons 3 and 5 are of mixed Celtic/Germanic origin.
See also...
Analysis of an ancient genome from Hinxton
Analysis of Hinxton2 - ERS389796
Analysis of Hinxton3 - ERS389797
Analysis of Hinxton4 - ERS389798
Analysis of Hinxton5 - ERS389799
Hinxton5, or ERS389799, is one of five ancient English genomes stored at the Sequence Read Archive under accession number ERP003900. However, this analysis is based on the genotype file of Hinxton5 available at Genetic Genealogy Tools. For more information and some speculation about these genomes see my earlier blog post here.
Despite its relatively low North Sea score in the Eurogenes K15, and pronounced western shift on the Principal Component Analysis (PCA) plots, this genome appears mostly Germanic. In my opinion, the shared drift stats and also oracle results are quite convincing in this regard. If this were a modern sample it could probably pass for 3/4 north Dutch and 1/4 Irish. By the way, the Sub-Saharan admixture just looks like noise; this is, after all, a low coverage genome.
Shared drift stats of the form f3(Mbuti;Hinxton5,Test) - Eurogenes dataset
Shared drift stats of the form f3(Mbuti;Hinxton5,Test) - Human Origins dataset
Eurogenes K15 4 Ancestors Oracle results
See also...
Analysis of Hinxton2 - ERS389796
Analysis of Hinxton3 - ERS389797
Analysis of Hinxton4 - ERS389798
Hinxton ancient genomes roundup
Not long ago I predicted that Ust'-Ishim belonged to a basal form of Y-chromosome haplogroup P (see here). As it turns out, the 45,000 year-old western Siberian genome belongs to K(xLT) or K-M526, which is actually pretty close to my guess. The Ust'-Ishim paper was published today and is sitting behind a paywall here, but the extensive supp info is free.
Here's a map to help visualize the information, featuring Ust'-Ishim as well as Mal'ta boy, another North Eurasian Upper Paleolithic genome published recently.
The Ust'-Ishim genome was sequenced from the fossil of a femur bone found on the right bank of the Irtysh River. This area is very close to the Urals, and almost in the middle of the former Mammoth steppe that once stretched across North Eurasia from Iberia to Alaska. Interestingly, M526 is an ancestral mutation to the markers that define Y-chromosome haplogroups N, Q and R, which possibly dominated North Eurasia since the Upper Paleolithic (note that the 24,000 year-old Mal'ta boy belongs to a basal form of R).
Moreover, R1a and R1b are the most frequent haplogroups in Europe today. Thus, it would seem that most European males derive their paternal ancestry from North Eurasian hunter-gatherers whose ancestors spread out across Eurasia from the Middle East over 45,000 years ago.
I know that a lot of people have been arguing recently that K-M526 and the derived P-M45 originated and diversified in Southeast Asia, and then migrated north well within the last 45,000 years (for instance, see here). However, considering that K-M526 was already in reindeer country 45,000 years ago, as well as the Denisovan (ancient Siberian hominin) admixture among Southeast Asians, that might well turn out to be the equivalent of arguing that up is down and down is up.
By the way, Ust'-Ishim also belongs to pan-Eurasian mitochondrial (mtDNA) haplogroup R*, and in terms of genome-wide genetic structure appears roughly intermediate between West and East Eurasians. These outcomes fit very nicely with its Y-haplogroup.
However, it's slightly closer to Mesolithic Iberian genome La Brana-1, Upper Paleolithic Siberian MA-1 (or Mal'ta boy), and present-day East Asians, than to present-day West Eurasians, including Europeans. That's because it lacks "ancestry from a population that did not participate in the initial dispersals of modern humans into Europe and Asia". This is obviously the so called Basal Eurasian admixture discussed in Lazaridis et al. (see here), which is probably associated with early Neolithic farmers.
Also worth mentioning is that Ust'-Ishim harbors longer stretches of Neanderthal chromosomal segments than present-day Eurasians, which suggests that admixture between modern humans and Neanderthals took place in the Middle East not long before the ancestors of Ust-Ishim moved into Siberia (50-60,000 years ago). But this was already covered months ago, and you'll find lots of links on the topic on Google.
Citation...
Qiaomei Fu et al., Genome sequence of a 45,000-year-old modern human from western Siberia, Nature 514, 445–449 (23 October 2014) doi:10.1038/nature13810
See also...
Y-haplogroup P1 in Pleistocene Siberia (Sikora et al. 2018 preprint)
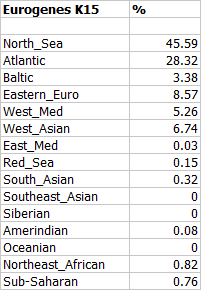
Hinxton4, or ERS389798, is one of five ancient English genomes stored at the Sequence Read Archive under accession number ERP003900. However, this analysis is based on the genotype file of Hinxton4 available at Genetic Genealogy Tools. For more information and some speculation about these genomes see my earlier blog post here.
I still don't know who these samples represent exactly, but in all likelihood, this is one of the two Iron Age sequences from the collection, and probably belongs to a Briton of Celtic stock. Note, for instance, its high affinity to the present-day Irish, relatively low North Sea score in the Eurogenes K15, and pronounced western shift on the second Principal Component Analysis (PCA) plot below.
Interestingly, Lithuanians top its shared drift list based on the Human Origins dataset and more than 360K SNPs. I'm not entirely sure what this means, but it's probably related in some way to the unusually high level (>45%) of indigenous European hunter-gatherer ancestry carried by Lithuanians.
Shared drift stats of the form f3(Mbuti;Hinxton4,Test) - Eurogenes dataset
Shared drift stats of the form f3(Mbuti;Hinxton4,Test) - Human Origins dataset
Eurogenes K15 4 Ancestors Oracle results
See also...
Analysis of Hinxton2 - ERS389796
Analysis of Hinxton3 - ERS389797
Analysis of Hinxton5 - ERS389799
Hinxton ancient genomes roundup