Showing posts with label Uralic. Show all posts
Showing posts with label Uralic. Show all posts
Sunday, November 19, 2023
Musaeum Scythia on the Seima-Turbino Phenomenon
A few weeks ago bioRxiv published two preprints on the Seima-Turbino Phenomenon (see here and here).
I can't say much about these manuscripts until I see the relevant ancient DNA samples, and that might take some time.
However, for now, I will say that both preprints really need to emphasize the profound impact that the Sintashta-related early Indo-Iranian speakers had on the Seima-Turbino Phenomenon. This, of course, would require Wolfgang Haak and friends to pull their heads out of their behinds and admit that the proto-Indo-Iranian homeland was in Eastern Europe, not in Iran.
At the same time, it's likely that the Seima-Turbino Phenomenon originated deep in Siberia, and its inception was probably most closely associated with the West Siberian Hunter-Gatherer (WSHG) genetic component. It's important that the preprints emphasize this too.
Moreover, I can't see any convincing arguments in either preprint that the Seima-Turbino Phenomenon was mainly associated with proto-Uralic speakers, or even that it was an important vector for the spread of proto-Uralic. So there's not much point in forcing the Uralic angle on studies focused on the Seima-Turbino Phenomenon. Indeed, what we also need is an archaeogenetics paper dealing specifically with the proto-Uralic expansion.
Apart from that, I'd like to direct your attention to the fact that Musaeum Scythia has already written a fine blog post about these preprints:
Genomic insights into the Seima-Turbino Phenomenon
See also...
Finally, a proto-Uralic genome
The Uralic cline with kra001 - no projection this time
Slavs have little, if any, Scytho-Sarmatian ancestry
Saturday, November 4, 2023
Slavs have little, if any, Scytho-Sarmatian ancestry
Here's an abstract of a new study from the David Reich Lab about ancient Slavs, titled "Genetic identification of Slavs in Migration Period Europe using an IBD sharing graph". Emphasis is mine:
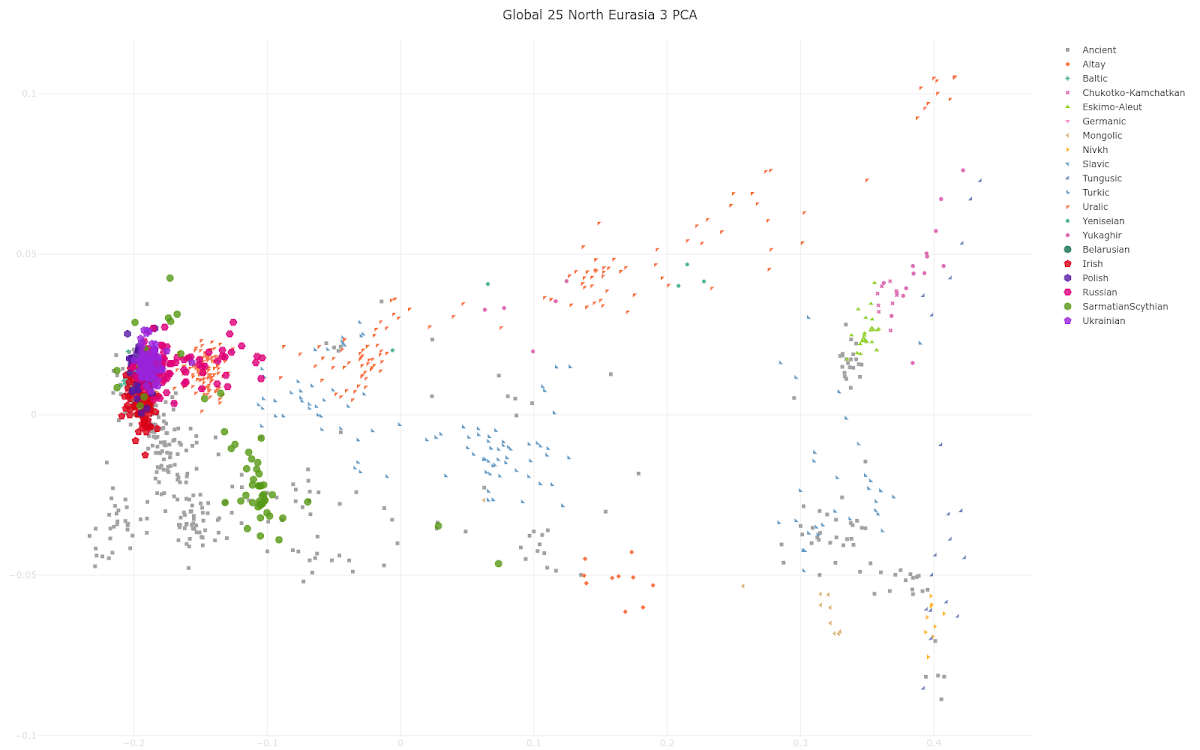 As you can see, dear reader, most of the Slavs (Belarusians, Poles, Ukrainians and many Russians) cluster with the Irish near the western end of the plot.
Some Russians are shifted significantly east of them along the "Uralic cline" and, as a result, they cluster with various Uralic speakers such as Mordovians. That's because when Slavs migrated deep into what is now northern Russia they mixed with Uralic speakers who were there before them.
Most of the Sarmatians and Scythians form a cluster southeast of the Slavs and Irish because they carry significant levels of East Asian ancestry. This type of eastern ancestry is basically missing in modern-day Slavs (see here).
Several of the Scythians cluster among the Slavs and Irish, but that's because they're genetic outliers, whose existence, if anything, suggests that some Scythians had significant Slavic-related and/or Irish-related ancestry.
Now, even though most of the Slavs do cluster with the Irish in the above PCA plot, I strongly disagree with the authors of the abstract when they claim that "differentiating Slavic, Germanic, and Celtic people is very difficult" with PCA. It's actually pretty damn easy and I've been doing it successfully for many years. For instance, see here.
See also...
Wielbark Goths were overwhelmingly of Scandinavian origin
The Caucasus is a semipermeable barrier to gene flow
As you can see, dear reader, most of the Slavs (Belarusians, Poles, Ukrainians and many Russians) cluster with the Irish near the western end of the plot.
Some Russians are shifted significantly east of them along the "Uralic cline" and, as a result, they cluster with various Uralic speakers such as Mordovians. That's because when Slavs migrated deep into what is now northern Russia they mixed with Uralic speakers who were there before them.
Most of the Sarmatians and Scythians form a cluster southeast of the Slavs and Irish because they carry significant levels of East Asian ancestry. This type of eastern ancestry is basically missing in modern-day Slavs (see here).
Several of the Scythians cluster among the Slavs and Irish, but that's because they're genetic outliers, whose existence, if anything, suggests that some Scythians had significant Slavic-related and/or Irish-related ancestry.
Now, even though most of the Slavs do cluster with the Irish in the above PCA plot, I strongly disagree with the authors of the abstract when they claim that "differentiating Slavic, Germanic, and Celtic people is very difficult" with PCA. It's actually pretty damn easy and I've been doing it successfully for many years. For instance, see here.
See also...
Wielbark Goths were overwhelmingly of Scandinavian origin
The Caucasus is a semipermeable barrier to gene flow
Popular methods of genetic analysis relying on allele frequencies such as PCA, ADMIXTURE and qpAdm are not suitable for distinguishing many populations that were important historical actors in the Migration Period Europe. For instance, differentiating Slavic, Germanic, and Celtic people is very difficult relying on these methods, but very helpful for archaeologists given a large proportion of graves with no inventory and frequent adoption of a different culture. To overcome these problems, we applied a method based on autosomal haplotypes. Imputation of missing genotypes and phasing was performed according to a protocol by Rubinacci et al. (2021), and IBD inference was done for ancient Eurasian individuals with data available at >600,000 1240K sites. IBD links for a subset of these individuals were represented as a graph, visualized with a force-directed layout algorithm, and clusters in this graph are inferred with the Leiden algorithm. One of the clusters in the IBD graph emerged that includes nearly all individuals in the dataset annotated archaeologically as “Slavic”. According to PCA a hypothesis for the origin of this population can be proposed: it was formed by admixture of a Baltic-related group with East Germanic people and Sarmatians or Scythians. The individuals belonging to the “Slavic” IBD sharing cluster form a chronological gradient on the PCA plot, with the earliest samples close to the Baltic LBA/EIA group. Later “Slavic” individuals are shifted to the right, closer to Central and Southern Europeans and probably reflecting further admixture of Slavs with local populations during the Migration Period.Apparently this abstract is causing a bit of confusion online because of the mention of possible Sarmatian or Scythian ancestry in Slavs. However, it's important to understand that the authors are referring to certain Slavic or even just Slavic-related individuals, usually from culturally heterogeneous frontier settlements deep in what is now Russia. So yes, it's possible that some of these individuals carry Sarmatian, Scythian or other exotic eastern ancestry. But even if this is true, then obviously we can't extend this inference to all ancient and modern-day Slavs. Indeed, below is a G25/Vahaduo Principal Component Analysis (PCA) that shows why modern-day Slavic speakers can't be linked genetically to Sarmatians or Scythians. To experience a more detailed version of the PCA paste the data here into the relevant field here.

Thursday, June 17, 2021
Balto-Slavic drift
A few years ago I began using the term "Balto-Slavic genetic drift" to describe the fine-scale genetic signal that is shared by the speakers of Baltic and Slavic languages to the exclusion of Europeans without significant Balto-Slavic ancestry.
As a result, nowadays, many people online use the term "Balto-Slavic drift" when referring to this phenomenon.
The easiest way to prove that Balto-Slavic drift exists is to run a fine-scale Principal Component Analysis (PCA) of European genetic variation with a lot of Balto-Slavic samples in the mix. Indeed, my Global25 PCA analysis does a great job of illustrating the impact of Balto-Slavic drift on the population structure of Europe both in PCA plots and mixture models (for instance, see here).
It's also possible to tease out Balto-Slavic drift with formal statistics. I showed this indirectly in a recent blog post about Greek population structure (see here). In this post I'm going to demonstrate how to explicitly and formally test for Balto-Slavic drift both in ancient and present-day samples.
To do this we need to find stats that basically split Baltic and Slavic speakers from other Europeans, such as f4(Outgroup,Test;Bell_Beaker_NDL,Baltic_LVA_BA). In this f4-stat, Baltic_LVA_BA is the ancient reference population with an unusually high level of Balto-Slavic drift, while Bell_Beaker_NDL is a fairly similar population overall in terms of ancient ancestry components, but with practically zero Balto-Slavic drift.
Note that the statistics with the most significant Z scores (>3) involve populations that speak Baltic or Slavic languages, or their neighbors who plausibly harbor significant Baltic and/or Slavic ancestry. Among the ancient, mostly Scandinavian, populations (from Margaryan et al. 2020 and marked with the VK2020 prefix), significant Balto-Slavic drift only appears in the more easterly and/or later groups from the Viking Age (VA).
 Unfortunately, one of the problems with this analysis is that Baltic_LVA_BA and Bell_Beaker_NDL aren't identical in terms of their ancient ancestry proportions. For one, the latter has significantly more Neolithic farmer ancestry. No wonder then, that Greeks, who are mostly of early farmer stock, don't show a significant Z score, despite probably packing a significant amount of Balto-Slavic ancestry dating to the Middle Ages.
In the near future, as more ancient samples become available, it might be possible to find better reference populations for the job and create more accurate, finer-scaled tests.
See also...
Uralian genes
That old chestnut: Northeast vs Northwest Euros
Unfortunately, one of the problems with this analysis is that Baltic_LVA_BA and Bell_Beaker_NDL aren't identical in terms of their ancient ancestry proportions. For one, the latter has significantly more Neolithic farmer ancestry. No wonder then, that Greeks, who are mostly of early farmer stock, don't show a significant Z score, despite probably packing a significant amount of Balto-Slavic ancestry dating to the Middle Ages.
In the near future, as more ancient samples become available, it might be possible to find better reference populations for the job and create more accurate, finer-scaled tests.
See also...
Uralian genes
That old chestnut: Northeast vs Northwest Euros

Monday, April 26, 2021
Uralians of the Sargat horizon
Many years ago, well before the start of the ancient DNA revolution, someone made the very clever inference that the N-Tat Y-chromosome marker was closely associated with the expansion of Uralic languages.
Since then, N-Tat has been renamed several times over, to the point that I no longer know what it's called, but the aforementioned inference has turned into a very solid consensus backed up by a wide range of studies focusing on modern and ancient DNA.
Nowadays, Y-haplogroup N-L1026, a subclade of N-Tat, is seen as the main genetic signal of the Uralic expansions, along, of course, with Nganasan-related genome-wide genetic ancestry.
A recent paper at Science Advances by Gnecchi-Ruscone et al. featured the first ever genome-wide samples from the Sargat horizon, which is an Iron Age archeological formation in western Siberia normally associated with the Ugric branch of the Uralic language family. Surprisingly, and disappointingly, the authors failed to investigate this widely accepted connection.
If we go by the Y-haplogroup classifications in the paper, which may or may not be the smart thing to do, at least two of the Sargat horizon males belong to N-L1026, and one also to the more derived N-Z1936 subclade, which has been found in the remains of Hungarian Conquerers from Medieval Hungary. Of course, Hungarian is an Ugric language generally thought to have been introduced into the Carpathian Basin by the Hungarian Conquerers who originally came from western Siberia.
That's probably enough to corroborate the association between the Sargat horizon and the spread of Ugric/Uralic languages, but let's also take a quick look at the autosomal DNA of these Sargat individuals. Firstly, here's a Principal Component Analysis (PCA), based on Global25 data and produced with the Vahaduo G25 Views online tool. The results are self-explanatory.
 Interestingly, I can't get a decent statistical fit when I try to reproduce the four-way qpWave/qpAdm model done by Gnecchi-Ruscone et al., probably mostly because my right pops or outgroups are different. This suggests to me that there's something important missing in their model.
Interestingly, I can't get a decent statistical fit when I try to reproduce the four-way qpWave/qpAdm model done by Gnecchi-Ruscone et al., probably mostly because my right pops or outgroups are different. This suggests to me that there's something important missing in their model.

Sargat_IA MNG_Khovsgol_LBA 0.203±0.045 RUS_Ekven_IA 0.183±0.044 RUS_Sintashta_MLBA 0.545±0.014 TKM_Gonur1_BA 0.068±0.013 chisq 16.805 tail prob 0.0186971 Full outputSo how about if I replace RUS_Ekven_IA with kra001, the oldest Nganasan-like individual in the ancient DNA record (see here), and MNG_Khovsgol_LBA with KAZ_Mereke_MBA, to add a more local stream of ancestry?
Sargat_IA KAZ_Mereke_MBA 0.135±0.017 kra001 0.301±0.007 RUS_Sintashta_MLBA 0.499±0.023 TKM_Gonur1_BA 0.066±0.015 chisq 8.872 tail prob 0.262001 Full outputThat's a better statistical fit and also, I'd say, a more realistic model, at least in terms of distal ancestry proportions. Note that Nganasan-related ancestry makes up 30% of the genome-wide genetic structure of the Sargat samples, which again corroborates the view that Uralic languages were spoken within the Sargat horizon. Update 28/04/21: This is the best qpAdm model that I could find for Sargat_IA, at least in terms of the chisq and tail prob. It shows that the Sargat population was in large part very similar to that of KAZ_Pazyryk_IA.
Sargat_IA KAZ_Mereke_MBA 0.032±0.016 KAZ_Pazyryk_IA 0.698±0.016 RUS_Sintashta_MLBA 0.236±0.021 TKM_Gonur1_BA 0.034±0.014 chisq 2.023 tail prob 0.958561 Full outputIt's missing kra001, because KAZ_Pazyryk_IA packs enough kra001-related ancestry for the job.
KAZ_Pazyryk_IA KAZ_Mereke_MBA 0.144±0.018 kra001 0.429±0.008 RUS_Sintashta_MLBA 0.378±0.026 TKM_Gonur1_BA 0.049±0.018 chisq 8.899 tail prob 0.259983 Full outputThe fact that KAZ_Pazyryk_IA can be modeled with significant kra001-related ancestry isn't surprising, considering that its territory was located in Siberia. However, my model doesn't necessarily prove that the Sargat population was largely or even partly of Pazyryk origin. Indeed, N-L1026 hasn't yet appeared in any Pazyryk remains. See also... The Uralic cline with kra001 - no projection this time First taste of Early Medieval DNA from the Ural region Hungarian Conquerors were rich in Y-haplogroup N More on the association between Uralic expansions and Y-haplogroup N It was always going to be this way On the association between Uralic expansions and Y-haplogroup N
Saturday, February 13, 2021
The Uralic cline with kra001 - no projection this time
A whole lot of nonsense was posted online, often by people who should've known better, after I claimed that kra001 was a solid proxy for a proto-Uralic genome (see here).
For those of you who still don't get it, below are three Principal Component Analysis (PCA) plots featuring Uralic speakers and other present-day Eurasians. Kra001 is also there. These graphs are based on genotype data not reprocessed Global25 data. The relevant datasheet is available here.
Compared to my previous PCA with kra001, here I included a bigger range of East Eurasian populations to help mitigate the effects of extreme genetic drift in some of the Siberian groups, at least on the first few Principal Components (PCs). Moreover, kra001 wasn't projected onto PCs computed with modern-day samples, so he was free to influence the outcome of the PCA.


 Note the east to west clines made up largely of Uralic speaking groups on the first two plots. These plots are based on PCs 1/2 and 1 /3, respectively. The third plot, based on PCs 1/4, is more complex and thus more difficult to interpret, but it also manages to isolate many of the Uralic populations from the others.
The Uralic-specific clines do intersect with the clines and clusters formed by the other linguistic groups. However, based on the three plots, the Yeniseian-speaking Kets are the only Asian group that can plausibly be confused for Uralic speakers.
Importantly, apart from the Kets, kra001 is the only Asian individual who shifts his position on all three plots as if he were a Uralic speaker. This might well be a coincidence, and we'll never know what language was spoken by kra001, but it does suggest to me that his genome is a solid proxy for a proto-Uralic genome.
See also...
First taste of Early Medieval DNA from the Ural region
The BOO people: earliest Uralic speakers in the ancient DNA record?
Fresh off the sledge
Note the east to west clines made up largely of Uralic speaking groups on the first two plots. These plots are based on PCs 1/2 and 1 /3, respectively. The third plot, based on PCs 1/4, is more complex and thus more difficult to interpret, but it also manages to isolate many of the Uralic populations from the others.
The Uralic-specific clines do intersect with the clines and clusters formed by the other linguistic groups. However, based on the three plots, the Yeniseian-speaking Kets are the only Asian group that can plausibly be confused for Uralic speakers.
Importantly, apart from the Kets, kra001 is the only Asian individual who shifts his position on all three plots as if he were a Uralic speaker. This might well be a coincidence, and we'll never know what language was spoken by kra001, but it does suggest to me that his genome is a solid proxy for a proto-Uralic genome.
See also...
First taste of Early Medieval DNA from the Ural region
The BOO people: earliest Uralic speakers in the ancient DNA record?
Fresh off the sledge



Friday, February 5, 2021
Finally, a proto-Uralic genome
Obviously, genes don't speak languages, people do. But sometimes it's possible to associate a linguistic group with a very specific genetic signature.
A while ago many of us in the blogosphere spotted an uncanny connection between the Uralic language family, Y-haplogroup N-L1026 and Nganasan-like genome-wide genetic ancestry.
As a result, we expected a Nganasan-like population rich in N-L1026 to eventually appear in the ancient DNA record, probably somewhere in Siberia and in burials from a likely proto-Uralic archeological culture. This hasn't happened yet, but we now have direct evidence that such a population must have existed somewhere deep in Siberia as early as the Bronze Age.
Kra001, whose genome was published recently along with Kilinc et al., belongs to a pre-N-L1026 lineage and, at least in terms of genome-wide genetic structure, could well be from a population directly ancestral to present-day Nganasans. Of course, the Nganasan language is part of the Samoyedic branch of Uralic.
Below is a series of Principal Component Analyses (PCA) featuring kra001. He's labeled RUS_Krasnoyarsk_BA, after the location and age of his burial. Note the obvious Uralic cline running across the plots. That is, from west to east. Kra001 is positioned at the end of this cline very close to a small cluster of Nganasans. To see interactive versions of the plots, paste the Global25 coordinates here into the relevant field here.


 Admittedly, there's no way of knowing whether this individual spoke proto-Uralic or not. Indeed, he may have spoken something totally unrelated. The important point is that the very specific genetic signature shared by almost all present-day Uralic speakers, except perhaps Hungarians, is now finally represented in the ancient DNA record. And I can reveal to you that we'll soon be seeing many more ancients very similar to kra001 in upcoming papers.
See also...
The Uralic cline with kra001 - no projection this time
The BOO people: earliest Uralic speakers in the ancient DNA record?
Fresh off the sledge
Admittedly, there's no way of knowing whether this individual spoke proto-Uralic or not. Indeed, he may have spoken something totally unrelated. The important point is that the very specific genetic signature shared by almost all present-day Uralic speakers, except perhaps Hungarians, is now finally represented in the ancient DNA record. And I can reveal to you that we'll soon be seeing many more ancients very similar to kra001 in upcoming papers.
See also...
The Uralic cline with kra001 - no projection this time
The BOO people: earliest Uralic speakers in the ancient DNA record?
Fresh off the sledge



Monday, July 27, 2020
Ancient ancestry proportions in present-day Europeans (to be continued)
This year has already been massive in all sorts of ways, including for new data and software releases. So I'm thinking it might be time to update many of the analyses that were featured at this blog a while ago.
Let's start with the classic hunter vs farmer vs herder mixture model for present-day European populations. The rules of the game are as follows:
- run the latest version of qpAdm using qpfstats output
- use transversion sites and 1240K capture data
- pick a set of diverse and chronologically sound outgroups
- for a model to be successful the p-value must reach 0.01
- tweak the left pops in models that are clearly underperforming
- follow high end scientific literature, logic and common sense
Obviously, the reason that I decided to limit my analysis to markers from transversion sites is to mitigate problems associated with modeling the ancestry of modern, high quality samples with relatively low quality ancients. One of these problems appears to be qpAdm assigning faux East Asian/Siberian admixture to present-day Europeans (for instance, see figure 4 here).
My starting reference populations and outgroups are listed below. In qpAdm terminology the former are known as the "left pops", while the latter as the "right pops". Most of these samples are freely available at the David Reich Lab website here.
left pops:
HUN_Koros_N_HG
TUR_Barcin_N
UKR_Yamnaya
TUR_Barcin_N
UKR_Yamnaya
right pops:
CMR_Shum_Laka_8000BP
MAR_Taforalt
Levant_Natufian
IRN_Ganj_Dareh_N
Levant_PPNB
CZE_Vestonice16
BEL_GoyetQ116-1
Iberia_ElMiron
RUS_Karelia_HG
RUS_West_Siberia_HG
MNG_North_N
RUS_Ust_Kyakhta
MAR_Taforalt
Levant_Natufian
IRN_Ganj_Dareh_N
Levant_PPNB
CZE_Vestonice16
BEL_GoyetQ116-1
Iberia_ElMiron
RUS_Karelia_HG
RUS_West_Siberia_HG
MNG_North_N
RUS_Ust_Kyakhta
As you can see, I picked a wide variety of right pops. But I chose most of them specifically to be able to differentiate the three streams of ancestry - from ancient hunters, farmers and herders - that are the focus of my analysis. I also intentionally avoided using samples in the right pops that may have experienced gene flow, including cryptic gene flow, from the populations in the left pops.
I somewhat speculatively earmarked HUN_Koros_N_HG, from the Early Neolithic Carpathian Basin, and UKR_Yamnaya, from the Early Bronze Age North Pontic steppe in what is now Ukraine, to represent the hunter-gatherer and pastoralist streams of ancestry, respectively.
That's because I expected HUN_Koros_N_HG to be the best proxy for the hunter-gatherer ancestry that was initially absorbed by the early farmers who fanned out from the Aegean region across much of the European continent, and of course it made sense to choose a steppe pastoralist population that was located close to Central Europe where such groups first made the biggest impact outside of the steppe.
Interestingly, HUN_Koros_N_HG and UKR_Yamnaya did prove to be among most effective choices for the types of ancestries that they represented. For instance, UKR_Yamnaya generally produced much stronger statistical fits than a very similar set of Yamnaya samples from the Caspian steppe (more precisely, from the Samara region in Russia). However, this might well be an artifact, due to very specific characteristics of these few ancient individuals. Larger sample sets would be welcome, especially from Yamnaya sites in Ukraine.
Below, dear audience, is a spreadsheet featuring the preliminary results. Click on the image to view and/or download the spreadsheet. The general rule is that the higher the tail prob, or p-value, the more likely it is that the ancestry proportions are close to the truth (a tail prob of well below 0.05 is usually a strong indication that something isn't right). For a detailed look at each of the qpAdm runs, feel free to consult the zip file here.

Note, however, that many of the European groups in my burgeoning genotype dataset are yet to make an appearance in the spreadsheet. That's because their models with the standard left pops showed p-values well under 0.01, which essentially meant that they failed, and I'm still trying to make them work.
But round one has certainly revealed some fascinating stuff. For instance, except for Hungarians and Estonians, none of the Uralic-speaking groups can be modeled successfully in the standard three-way model.
However, I managed to significantly improve the statistical fits in their models by adding a Siberian population, RUS_Baikal_BA, to the left pops. This is unlikely to be a coincidence, because the Proto-Uralic homeland was almost certainly located in or very near Siberia. Iain Mathieson please take note.
Saami
HUN_Koros_N_HG 0.134±0.043
RUS_Baikal_BA 0.270±0.015
TUR_Barcin_N 0.081±0.026
UKR_Yamnaya 0.515±0.058
HUN_Koros_N_HG 0.134±0.043
RUS_Baikal_BA 0.270±0.015
TUR_Barcin_N 0.081±0.026
UKR_Yamnaya 0.515±0.058
chisq 19.865
tail prob 0.0108571
See also...
Tuesday, July 14, 2020
First taste of Early Medieval DNA from the Ural region (Csaky et al. 2020 preprint)
Over at bioRxiv at this LINK. From the preprint:


 Csaky et al., Early Medieval Genetic Data from Ural Region Evaluated in the Light of Archaeological Evidence of Ancient Hungarians, bioRxiv, Posted July 13, 2020, doi: https://doi.org/10.1101/2020.07.13.200154
See also...
Hungarian Conquerors were rich in Y-haplogroup N
On the association between Uralic expansions and Y-haplogroup N
More on the association between Uralic expansions and Y-haplogroup N
Ancient DNA confirms the link between Y-haplogroup N and Uralic expansions
Csaky et al., Early Medieval Genetic Data from Ural Region Evaluated in the Light of Archaeological Evidence of Ancient Hungarians, bioRxiv, Posted July 13, 2020, doi: https://doi.org/10.1101/2020.07.13.200154
See also...
Hungarian Conquerors were rich in Y-haplogroup N
On the association between Uralic expansions and Y-haplogroup N
More on the association between Uralic expansions and Y-haplogroup N
Ancient DNA confirms the link between Y-haplogroup N and Uralic expansions
The ancient Hungarians originated from the Ural region of Russia, and migrated through the Middle-Volga region and the Eastern European steppe into the Carpathian Basin during the 9th century AD. Their Homeland was probably in the southern Trans-Ural region, where the Kushnarenkovo culture disseminated. In the Cis-Ural region Lomovatovo and Nevolino cultures are archaeologically related to ancient Hungarians. In this study we describe maternal and paternal lineages of 36 individuals from these regions and nine Hungarian Conquest period individuals from today's Hungary, as well as shallow shotgun genome data from the Trans-Uralic Uyelgi cemetery. We point out the genetic continuity between the three chronological horizons of Uyelgi cemetery, which was a burial place of a rather endogamous population. Using phylogenetic and population genetic analyses we demonstrate the genetic connection between Trans-, Cis-Ural and the Carpathian Basin on various levels. The analyses of this new Uralic dataset fill a gap of population genetic research of Eurasia, and reshape the conclusions previously drawn from 10-11th century ancient mitogenomes and Y-chromosomes from Hungary. ... Majority of Uyelgi males belonged to Y chromosome haplogroup N, and according to combined STR, SNP and Network analyses they belong to the same subclade within N-M46 (also known as N-tat and N1a1-M46 in ISOGG 14.255). N-M46 nowadays is a geographically widely distributed paternal lineage from East of Siberia to Scandinavia 33 . One of its subclades is N-Z1936 (also known as N3a4 and N1a1a1a1a2 in ISOGG 14.255), which is prominent among Uralic speaking populations, probably originated from the Ural region as well and mainly distributed from the West of Ural Mountains to Scandinavia (Finland). Seven samples of Uyelgi site most probably belong to N-Y24365 (also known as N-B545 and N1a1a1a1a2a1c2 in ISOGG 14.255) under N-Z1936, a specific subclade that can be found almost exclusively in todays’ Tatarstan, Bashkortostan and Hungary 17 (ISOGG, Yfull).



Tuesday, July 7, 2020
On the exotic origins of the Hungarian Arpad Dynasty (Nagy et al. 2020)
Hungarians speak a Uralic and Finno-Ugric language. However, the founders of the Medieval Hungarian state, the Arpad Dynasty, probably had Irano-Turkic paternal origins. There's a very interesting new paper on this topic at the European Journal of Human Genetics (see here). From the paper, emphasis is mine:
The phylogenetic origins of the Hungarians who occupied the Carpathian basin has been much contested [40]. Based on linguistic arguments it was proposed that they represented a predominantly Finno-Ugric speaking population while the oral and written tradition of the Árpád dynasty suggests a relationship with the Huns. Based on the genetic analysis of two members of the Árpád Dynasty, it appears that they derived from a lineage (R-Z2125) that is currently predominantly present among ethnic groups (Pashtun, Tadjik, Turkmen, Uzbek, and Bashkir) speaking Iranian or Turkic languages. However, their closest kin, the Bashkirs live in close proximity with Finno-Ugric speaking populations with the N-B539 haplogroup. A recent study shows that this haplogroup is also found in modern Hungarians [41]. Intriguingly, the most recent separation of the N-B539 derived lineages found in Hungarians and Bashkirs is estimated to have occurred ~2000 years before present [42]. This would suggest that a group of people consisting of a Turkic (R-SUR51) component and a Finno-Ugric (N-B539) component left the Volga Ural region about 2000 years ago and started a migration that eventually culminated in settlement in the Carpathian Basin.Citation... Nagy, P.L., Olasz, J., Neparáczki, E. et al. Determination of the phylogenetic origins of the Árpád Dynasty based on Y chromosome sequencing of Béla the Third. Eur J Hum Genet (2020). https://doi.org/10.1038/s41431-020-0683-z See also... Hungarian Conquerors were rich in Y-haplogroup N On the association between Uralic expansions and Y-haplogroup N More on the association between Uralic expansions and Y-haplogroup N Ancient DNA confirms the link between Y-haplogroup N and Uralic expansions
Tuesday, January 14, 2020
Hungarian Conquerors were rich in Y-haplogroup N (Fóthi et al. 2020)
Open access at Archaeological and Anthropological Sciences at this LINK. Below is the paper abstract. Emphasis is mine:
 Fóthi, E., Gonzalez, A., Fehér, T. et al., Genetic analysis of male Hungarian Conquerors: European and Asian paternal lineages of the conquering Hungarian tribes, Archaeol Anthropol Sci (2020) 12: 31. https://doi.org/10.1007/s12520-019-00996-0
See also...
On the association between Uralic expansions and Y-haplogroup N
More on the association between Uralic expansions and Y-haplogroup N
Ancient DNA confirms the link between Y-haplogroup N and Uralic expansions
Fóthi, E., Gonzalez, A., Fehér, T. et al., Genetic analysis of male Hungarian Conquerors: European and Asian paternal lineages of the conquering Hungarian tribes, Archaeol Anthropol Sci (2020) 12: 31. https://doi.org/10.1007/s12520-019-00996-0
See also...
On the association between Uralic expansions and Y-haplogroup N
More on the association between Uralic expansions and Y-haplogroup N
Ancient DNA confirms the link between Y-haplogroup N and Uralic expansions
According to historical sources, ancient Hungarians were made up of seven allied tribes and the fragmented tribes that split off from the Khazars, and they arrived from the Eastern European steppes to conquer the Carpathian Basin at the end of the ninth century AD. Differentiating between the tribes is not possible based on archaeology or history, because the Hungarian Conqueror artifacts show uniformity in attire, weaponry, and warcraft. We used Y-STR and SNP analyses on male Hungarian Conqueror remains to determine the genetic source, composition of tribes, and kin of ancient Hungarians. The 19 male individuals paternally belong to 16 independent haplotypes and 7 haplogroups (C2, G2a, I2, J1, N3a, R1a, and R1b). The presence of the N3a haplogroup is interesting because it rarely appears among modern Hungarians (unlike in other Finno-Ugric-speaking peoples) but was found in 37.5% of the Hungarian Conquerors. This suggests that a part of the ancient Hungarians was of Ugric descent and that a significant portion spoke Hungarian. We compared our results with public databases and discovered that the Hungarian Conquerors originated from three distant territories of the Eurasian steppes, where different ethnicities joined them: Lake Baikal-Altai Mountains (Huns/Turkic peoples), Western Siberia-Southern Urals (Finno-Ugric peoples), and the Black Sea-Northern Caucasus (Caucasian and Eastern European peoples). As such, the ancient Hungarians conquered their homeland as an alliance of tribes, and they were the genetic relatives of Asiatic Huns, Finno-Ugric peoples, Caucasian peoples, and Slavs from the Eastern European steppes.

Monday, December 9, 2019
The BOO people: earliest Uralic speakers in the ancient DNA record?
N-L1026 is the Y-chromosome haplogroup most closely associated with the speakers of Uralic languages. Thus far, the oldest published instances of N-L1026 are in two Siberian-like samples dating to 1473±87 calBCE from the site of Bolshoy Oleni Ostrov (BOO), located within the Arctic Circle in the Kola Peninsula, northern Russia.
So does this mean that the BOO people were Uralic speakers? I'm now thinking that it probably does, even though, as the scientists who published the BOO samples a year ago pointed out, they predate most estimates of the spread of extant Uralic languages into the Kola Peninsula (see Lamnidis et al. here).
Hundreds of ancient human samples from across Eurasia have been sequenced since last year. In fact, thousands if we count unpublished data. But only a handful of them belong to N-L1026.
Indeed, as far as I know, the next oldest instance of N-L1026 from Europe after those at BOO is still in an Iron Age sample from what is now Estonia published earlier this year as 0LS10. Of course, this individual was in all likelihood an early west Uralic (Finnic) speaker (see Saag et al. here).
Moreover, consider these comments by Murashkin et al. in regards to the BOO site (referred to as KOG in their paper, available here):
 Below is a Principal Component Analysis (PCA) based on Global25 data featuring the earliest likely Uralic speakers in the ancient DNA record. It was produced with an online PCA runner freely available here. EST_IA includes the above mentioned 0LS10, while FIN_Levanluhta_IA is largely made up of Saami-related samples from western Finland. See anything interesting? Feel free to let me know about it in the comments below.
Below is a Principal Component Analysis (PCA) based on Global25 data featuring the earliest likely Uralic speakers in the ancient DNA record. It was produced with an online PCA runner freely available here. EST_IA includes the above mentioned 0LS10, while FIN_Levanluhta_IA is largely made up of Saami-related samples from western Finland. See anything interesting? Feel free to let me know about it in the comments below.
 See also...
Big deal of 2019: ancient DNA confirms the link between Y-haplogroup N and Uralic expansions
It was always going to be this way
More on the association between Uralic expansions and Y-haplogroup N
See also...
Big deal of 2019: ancient DNA confirms the link between Y-haplogroup N and Uralic expansions
It was always going to be this way
More on the association between Uralic expansions and Y-haplogroup N
Most of the bodies had been buried in wooden, boat-shaped, lidded caskets, which looked like small boats or traditional Sámi sledges (Ru. kerezhka). ... The morphological characteristics of the skull series of the KOG are not like those of any other ancient or modern series from the Kola Peninsula, including the Sámi people. Instead, the series shows closer biological affinities with ancient Altai Neolithic and modern, Ugric-speaking Siberian groups (Moiseyev & Khartanovich 2012). It has earlier been suggested that modern Ugric-speaking Siberians, together with Samoyeds and Volga Finnic populations, share some common morphological characteristics that indicate their common origin (Alekseyev 1974; Bunak 1956; Gokhman 1992). ... Based on the materials from the grave field, we can argue that there were direct or indirect contacts between the inhabitants of the Kola Peninsula and southern and western Scandinavia (Murashkin & Tarasov 2013).Thus, the BOO people may have spoken an early west Uralic language related to Sami languages. It's also possible that they are in part ancestral to the N-L1026-rich Sami people. Another intriguing thing about these mysterious ancients is that individual BOO003 belongs to the rare mitochondrial haplogroup T2d1b1. Now, this clearly is not a lineage native to Europe or indeed any part of North Eurasia. Its ultimate source is probably West or Central Asia. So how did this pioneer polar explorer end up with such an unusual and exotic mtDNA marker, and might the answer be an important clue about the origins of the BOO people? The most plausible explanation is that the ancestors of BOO003 were associated with the Seima-Turbino phenomenon, which stretched from the taiga zone to the oases of what is now western China along the Ob-Irtysh river system, and probably facilitated cultural, linguistic and genetic exchanges between the populations of North Eurasia and Central Asia. In other words, considering all of the clues, it would seem that the BOO people came from some part of the Ob-Irtysh basin, which might thus be the best place to look for the population with the oldest and phylogenetically most basal N-L1026 lineages. And if we find that, then we've probably found the proto-Uralians and their homeland.


Sunday, December 1, 2019
Big deal of 2019: ancient DNA confirms the link between Y-haplogroup N and Uralic expansions
The academic consensus is that Indo-European languages first spread into the Baltic region from the Eastern European steppes along with the Corded Ware culture (CWC) and its people during the Late Neolithic, well before the expansion of Uralic speakers into Fennoscandia and surrounds, probably from somewhere around the Ural Mountains.
On the other hand, the views that the Uralic language family is native to Northern Europe and/or closely associated with the CWC are fringe theories usually espoused by people not familiar with the topic or, unfortunately it has to be said, mentally unstable trolls.
The likely close relationship between the CWC expansion and the early spread of Indo-European languages was discussed in several papers in recent years (for instance, see here). This year, we saw the first ancient DNA paper focusing on the transition from the Bronze Age to the Iron Age in the East Baltic, including the likely first arrival of Uralic speech in what is now Estonia.
Published in Current Biology courtesy of Saag et al., the paper showed that the genetic structure of present-day East Baltic populations largely formed in the Iron Age (see here). It was during this time, the authors revealed, that the region experienced a sudden influx of Y-chromosome haplogroup N, which is today common in many Uralic speaking populations and often referred to as a Proto-Uralic marker. Little wonder then that Saag et al. linked this genetic shift in the East Baltic to the westward migrations of early Uralic speakers.
The table below, based on data from the Saag et al. paper, surely doesn't leave much to the imagination about what happened.
 Unfortunately, I have to say that the genome-wide analysis in the paper was less informative than it could have been. The authors focused their attention on rather broad genetic components, and, as a result, missed an interesting fine scale distinction between their Bronze Age and Iron Age samples. The spatial maps below, based on my Global25 data for most of the ancients from Saag et al., show what I mean. The hotter the color the higher the genetic similarity between them and present-day West Eurasian populations.
Note that the Bronze Age (Baltic_EST_BA) samples are most similar to the Baltic-speaking, and thus also Indo-European-speaking, Latvians and Lithuanians, rather than the Uralic-speaking Estonians, even though they're from burial sites in Estonia. On the other hand, the Iron Age (Baltic_EST_IA) samples show strong similarity to a wider range of populations, including Estonians and many other Uralic-speaking groups.
Unfortunately, I have to say that the genome-wide analysis in the paper was less informative than it could have been. The authors focused their attention on rather broad genetic components, and, as a result, missed an interesting fine scale distinction between their Bronze Age and Iron Age samples. The spatial maps below, based on my Global25 data for most of the ancients from Saag et al., show what I mean. The hotter the color the higher the genetic similarity between them and present-day West Eurasian populations.
Note that the Bronze Age (Baltic_EST_BA) samples are most similar to the Baltic-speaking, and thus also Indo-European-speaking, Latvians and Lithuanians, rather than the Uralic-speaking Estonians, even though they're from burial sites in Estonia. On the other hand, the Iron Age (Baltic_EST_IA) samples show strong similarity to a wider range of populations, including Estonians and many other Uralic-speaking groups.


 See also...
It was always going to be this way
Fresh off the sledge
More on the association between Uralic expansions and Y-haplogroup N
See also...
It was always going to be this way
Fresh off the sledge
More on the association between Uralic expansions and Y-haplogroup N




Saturday, June 1, 2019
They came, they saw, and they mixed
Y-chromosome haplogroup N is strongly associated with Uralic-speaking populations. That's probably because it was a salient feature of the gene pool of the earliest Uralic speakers, and it went with them as they migrated across northern Eurasia. However, some of its younger subclades appear to have spread with the speakers of Indo-European and Turkic languages.
For instance, N-Y10931 seems to be a marker of the Rurikids, a Varangian dynasty that, according to most sources, ruled the Kievan Rus in what are now Russia and Ukraine. And the Kievan Rus was a lose medieval political federation in which Slavic, Finnic (west Uralic) and Germanic languages were probably spoken. The latest on the genetic genealogy of the Rurikids was presented a couple of days ago at the Centenary of Human Population Genetics conference in Moscow, and there's an abstract of the talk available here (download the PDF and scroll down to page 84).
I'm not aware of any Rurikids among the thousands of ancients in my dataset, or even of any samples belonging to N-Y10931. But I do have the genome of someone who belongs to N-Y4339, which, as per the abstract linked to above, is proximally ancestral to N-Y10931. Not only does this person come from Viking Age Scandinavia, but he was buried in a crouched position typical of Slavic funerary customs of the time.
The individual in question is vik_84001. His genome was published recently along with a paper on the population structure of the Swedish town of Sigtuna way back when it was a Viking stronghold (see here). This is where his Y-chromosome sequence, labeled ERS2540883, is positioned on the YFull Y-chromosome phylogenetic tree. Click on the image to go to YFull.
 However, the result is likely to be compromised to some extent by missing data. If so, it's possible that vik_84001 does indeed belong to N-Y10931 and ought to be sitting near or even among that cluster of Russian samples (Rurik descendants?) at the bottom of the page.
In any case, vik_84001 seems to be the closest individual in the ancient DNA record to a Rurikid. The Principal Component Analysis (PCA) below is based on my Global25 data. It features 18 other Viking Age individuals from Sigtuna alongside vik_84001 (look for the black dots). The relevant datasheet is available here. Interestingly, despite his eastern Y-haplogroup, vik_84001 is one of the few Sigtuna ancients who clusters strongly with present-day Swedes.
However, the result is likely to be compromised to some extent by missing data. If so, it's possible that vik_84001 does indeed belong to N-Y10931 and ought to be sitting near or even among that cluster of Russian samples (Rurik descendants?) at the bottom of the page.
In any case, vik_84001 seems to be the closest individual in the ancient DNA record to a Rurikid. The Principal Component Analysis (PCA) below is based on my Global25 data. It features 18 other Viking Age individuals from Sigtuna alongside vik_84001 (look for the black dots). The relevant datasheet is available here. Interestingly, despite his eastern Y-haplogroup, vik_84001 is one of the few Sigtuna ancients who clusters strongly with present-day Swedes.
 But here's what happens when I model his ancestry proportions with the Global25/nMonte method using a wide range of reference populations from Northern and Eastern Europe. The Swedes in this model are the same as those in the PCA.
But here's what happens when I model his ancestry proportions with the Global25/nMonte method using a wide range of reference populations from Northern and Eastern Europe. The Swedes in this model are the same as those in the PCA.

vik_84001 Swedish,84.6 Ingrian,9.2 Russian_Tver,6.2 Belarusian,0 Estonian,0 Finnish,0 Finnish_East,0 Karelian,0 Latvian,0 Mordovian,0 Russian_Kostroma,0 Russian_Kursk,0 Russian_Orel,0 Russian_Pinega,0 Russian_Smolensk,0 Russian_Voronez,0 Ukrainian,0 Vepsian,0 [1] "distance%=2.3778"Yep, despite his position in the PCA, vik_84001 shows a strong signal of ancestry related to the present-day populations of northwestern Russia. I'm not sure what this means exactly, but it's certainly fascinating stuff. And, by the way, I usually wouldn't use so many similar reference populations in a single Global25/nMonte model because of the problem of "overfitting", but in some cases it's OK to do so if the nMonte algorithm has enough recent genetic drift to latch onto. See also... More on the association between Uralic expansions and Y-haplogroup N Fresh off the sledge Uralic-specific genome-wide ancestry did make a signifcant impact in the East Baltic It was always going to be this way Conan the Barbarian probably belonged to Y-haplogroup R1a
Friday, May 24, 2019
More on the association between Uralic expansions and Y-haplogroup N
Genes don't speak languages, people do. Thus, associations between genetic markers and languages may often not be easy to discern, especially with time. This is the case when it comes to Y-chromosome haplogroup N and the Hungarian language.
I briefly discussed this problem not long ago in the context of new ancient DNA samples from medieval Hungary (see here). Today, a detailed paper on the topic by Post et al. was published at Scientific Reports (open access here). It brings together evidence from modern and ancient DNA, linguistics and archeology to argue that Hungarian was introduced into the Carpathian Basin during the Middle Ages by migrants from near the Ural Mountains rich in Y-haplogroup N3a4-B539. Below is the paper abstract, emphasis is mine:
 Post et al., Y-chromosomal connection between Hungarians and geographically distant populations of the Ural Mountain region and West Siberia, Scientific Reports 9, Article number: 7786 (2019), DOI: https://doi.org/10.1038/s41598-019-44272-6
See also...
Hungarian Conquerors were rich in Y-haplogroup N (Fóthi et al. 2020)
On the association between Uralic expansions and Y-haplogroup N
Ancient DNA confirms the link between Y-haplogroup N and Uralic expansions
Post et al., Y-chromosomal connection between Hungarians and geographically distant populations of the Ural Mountain region and West Siberia, Scientific Reports 9, Article number: 7786 (2019), DOI: https://doi.org/10.1038/s41598-019-44272-6
See also...
Hungarian Conquerors were rich in Y-haplogroup N (Fóthi et al. 2020)
On the association between Uralic expansions and Y-haplogroup N
Ancient DNA confirms the link between Y-haplogroup N and Uralic expansions
Hungarians who live in Central Europe today are one of the westernmost Uralic speakers. Despite of the proposed Volga-Ural/West Siberian roots of the Hungarian language, the present-day Hungarian gene pool is highly similar to that of the surrounding Indo-European speaking populations. However, a limited portion of specific Y-chromosomal lineages from haplogroup N, sometimes associated with the spread of Uralic languages, link modern Hungarians with populations living close to the Ural Mountain range on the border of Europe and Asia. Here we investigate the paternal genetic connection between these spatially separated populations. We reconstruct the phylogeny of N3a4-Z1936 clade by using 33 high-coverage Y-chromosomal sequences and estimate the coalescent times of its sub-clades. We genotype close to 5000 samples from 46 Eurasian populations to show the presence of N3a4-B539 lineages among Hungarians and in the populations from Ural Mountain region, including Ob-Ugric-speakers from West Siberia who are geographically distant but linguistically closest to Hungarians. This sub-clade splits from its sister-branch N3a4-B535, frequent today among Northeast European Uralic speakers, 4000–5000 ya, which is in the time-frame of the proposed divergence of Ugric languages.

Thursday, May 16, 2019
Fresh off the sledge
As things stand, the closest individual to a Proto-Uralic speaker in the ancient DNA record is arguably 0LS10 from an Iron Age tarand grave in what is now Estonia. I say that because:

 Note that 0LS10 doesn't cluster strongly with any ancient or modern populations. To investigate this in more detail I ran a series of two-way qpAdm analyses, testing tens of ancient individuals and populations as potential admixture sources. These two models stood out above the rest in terms of their statistical fits, chronology and overall plausibility.
Note that 0LS10 doesn't cluster strongly with any ancient or modern populations. To investigate this in more detail I ran a series of two-way qpAdm analyses, testing tens of ancient individuals and populations as potential admixture sources. These two models stood out above the rest in terms of their statistical fits, chronology and overall plausibility.

- isotopic data suggest that 0LS10 wasn't born where he died, and considering his elevated Siberian ancestry relative to earlier and most contemporaneous Baltic ancients, he was very likely a migrant to the Baltic region from the east - the tarand grave tradition appears to be specifically a Finnic (west Uralic) phenomenon that probably spread from the Volga-Oka region, which is just west of where most people place the Proto-Uralic homeland - 0LS10 belongs to Y-chromosome haplogroup N-L1026, a paternal marker that is especially closely associated with Uralic-speaking populations and probably only appeared in the East Baltic region during the transition from the Bronze Age to the Iron Age
You can find more background info about 0LS10 and other relevant samples in Saag et al. 2019 (see here). This is where he sits in my Principal Component Analyses (PCA) focusing on fine scale Northern European genetic diversity. The relevant datasheets are available here and here, respectively.

Baltic_EST_IA_0LS10 Baltic_EST_BA 0.826±0.045 RUS_Sintashta_MLBA_o1 0.174±0.045 chisq 12.527 tail prob 0.564048 Full output Baltic_EST_IA_0LS10 Baltic_EST_BA 0.683±0.102 RUS_Mezhovskaya 0.317±0.102 chisq 13.811 tail prob 0.463864 Full outputPlease note that RUS_Sintashta_MLBA_o1 isn't representative of the Sintashta culture population as a whole. It's a group of the most extreme genetic outliers among the Sintashta samples, and they may or may not have been Uralic speakers (see here). Interestingly, the Mezhovskaya culture population is generally associated with the Ugric branch of the Uralic language family. I was also able to closely replicate these results with the Global25/nMonte method; down to almost one per cent. However, the statistical fits (distances) are poor, probably because the reference populations aren't the real mixture sources. This is in line with the fact that their Y-haplogroups are Q1a, R1a and R1b, rather than any type of N.
Baltic_EST_IA:0LS10 Baltic_EST_BA,83.8 RUS_Sintashta_MLBA_o1,16.2 distance%=4.7955 Baltic_EST_IA:0LS10 Baltic_EST_BA,69.8 RUS_Mezhovskaya,30.2 distance%=3.5783
I do realize that two Bronze Age samples from Bolshoy Oleni Ostrov, Kola Peninsula, belong to N-L1026, but adding them to my mixture models doesn't help. Little wonder, because the Kola Peninsula lies within the Arctic Circle, and I'm pretty sure that 0LS10 and his N-L1026 came from somewhere just north of the mixture cline marked on the map below. Unfortunately, I can't test this directly yet due to the scarcity of ancient samples from this region.

Saturday, May 11, 2019
Uralic-specific genome-wide ancestry did make a signifcant impact in the East Baltic
I've started analyzing the ancient genotype data from the recent Saag et al. paper on the expansion of Uralic languages and associated spread of Siberian ancestry into the East Baltic region. The paper is freely available here and the data are here.
I really like the paper, but I don't agree with the authors' claim that the appearance of Y-chromosome haplogroup N in what is now Estonia and surrounds during the Iron Age is "not matched by a clear shift in autosomal profiles". In my opinion it certainly is, and, as one would expect, it's a shift towards a genetic profile typical of western Uralic speakers.
I'd say that the easiest way to find this signal is with a Principal Component Analysis (PCA) focusing on fine scale genetic substructures within Northern Europe, like the one below. The relevant datasheet is available here.
 Note that the East Baltic Iron Age samples, all from burial sites in what is now Estonia, appear to be peeling away from their Bronze Age predecessors and overlapping strongly with present-day Estonians, who are Uralic speakers. Indeed, the PCA suggests to me that the formation of the greater part of the present-day Estonian gene pool took place in the East Baltic during the transition from the Bronze Age to the Iron Age. That is, when Uralic languages are generally accepted to have arrived in the region from near the Ural Mountains in the east.
I was also able to closely replicate these outcomes with my Global25 data using the method described here. However, in this effort, present-day Estonians are clearly more western than the Estonian Iron Age samples (EST_IA), which might be due to the presence of low level Germanic ancestry in Estonia dating to the medieval period. The relevant datasheet is available here.
Note that the East Baltic Iron Age samples, all from burial sites in what is now Estonia, appear to be peeling away from their Bronze Age predecessors and overlapping strongly with present-day Estonians, who are Uralic speakers. Indeed, the PCA suggests to me that the formation of the greater part of the present-day Estonian gene pool took place in the East Baltic during the transition from the Bronze Age to the Iron Age. That is, when Uralic languages are generally accepted to have arrived in the region from near the Ural Mountains in the east.
I was also able to closely replicate these outcomes with my Global25 data using the method described here. However, in this effort, present-day Estonians are clearly more western than the Estonian Iron Age samples (EST_IA), which might be due to the presence of low level Germanic ancestry in Estonia dating to the medieval period. The relevant datasheet is available here.
 Interestingly, the Estonian Bronze Age samples (EST_BA) come from stone-cist graves which are widely hypothesized to have been introduced to the East Baltic from the Nordic Bronze Age civilization. I even recall reading a paper on the topic which claimed that the remains buried in such graves were those of Proto-Germanic-speaking Scandinavian migrants. Well, I haven't had a chance to study these samples in any great detail yet, but considering that in both of the PCA above they're overlapping strongly with Latvian Bronze Age samples (LVA_BA) and sitting far away from the nearest Scandinavians, I'd say they're probably of local stock from way back.
See also...
It was always going to be this way
On the association between Uralic expansions and Y-haplogroup N
Inferring the linguistic affinity of long dead and non-literate peoples: a multidisciplinary approach
Interestingly, the Estonian Bronze Age samples (EST_BA) come from stone-cist graves which are widely hypothesized to have been introduced to the East Baltic from the Nordic Bronze Age civilization. I even recall reading a paper on the topic which claimed that the remains buried in such graves were those of Proto-Germanic-speaking Scandinavian migrants. Well, I haven't had a chance to study these samples in any great detail yet, but considering that in both of the PCA above they're overlapping strongly with Latvian Bronze Age samples (LVA_BA) and sitting far away from the nearest Scandinavians, I'd say they're probably of local stock from way back.
See also...
It was always going to be this way
On the association between Uralic expansions and Y-haplogroup N
Inferring the linguistic affinity of long dead and non-literate peoples: a multidisciplinary approach
Thursday, May 9, 2019
It was always going to be this way
The native peoples of the East Baltic - Estonians, Latvians and Lithuanians - are genetically alike and their paternal gene pools are dominated by the same two Y-chromosome haplogroups: R1a and N3a.
Linguistically, however, Estonians are a world apart from Latvians and Lithuanians. That's because the Estonian language belongs to the Uralic language family, which has an obvious North Eurasian character. On the other hand, Latvian and Lithuanian are both classified as Indo-European languages, along with the vast majority of other European languages.
The Uralic and Indo-European language families may or may not descend from the same ancestral tongue, but even if they do, their relationship is very distant.
So how is it that Estonians came to speak a Uralic language? As far back as I can remember, the basic explanation accepted by most people was that Uralic speech arrived in what is now Estonia and neighboring Finland during the Bronze Age with migrants, or perhaps invaders, rich in N3a from somewhere around the Ural Mountains. Conversely, Latvians and Lithuanians were generally assumed to have retained the Indo-European speech of their R1a-rich forefathers from the Pontic-Caspian steppe, who colonized much of Eastern Europe north of the steppe during the Late Neolithic.
Ancient DNA has now uncannily corroborated these theories (for instance, see Mittnik et al. 2018 and, published today, Saag et al. 2019). All it took was a handful of samples from a few relevant sites. I think that's awesome; I love it when sensible, long-standing hypotheses are validated by cutting edge science.
I'll have a lot more to say about the spread of Uralic languages and Uralian genes to the East Baltic when I get my hands on the genotype data from the new Saag et al. paper. I also have a post coming soon about the Nordic Bronze Age. Stay tuned.
 Update 10/05/2019: Uralic-specific genome-wide ancestry did make a signifcant impact in the East Baltic
See also...
Late PIE ground zero now obvious; location of PIE homeland still uncertain, but...
Corded Ware people =/= Proto-Uralics (Tambets et al. 2018)
Inferring the linguistic affinity of long dead and non-literate peoples: a multidisciplinary approach
Update 10/05/2019: Uralic-specific genome-wide ancestry did make a signifcant impact in the East Baltic
See also...
Late PIE ground zero now obvious; location of PIE homeland still uncertain, but...
Corded Ware people =/= Proto-Uralics (Tambets et al. 2018)
Inferring the linguistic affinity of long dead and non-literate peoples: a multidisciplinary approach
Sunday, April 7, 2019
On the association between Uralic expansions and Y-haplogroup N
Almost all present-day populations speaking Uralic languages show moderate to high frequencies of Y-chromosome haplogroup N. I reckon there are two likely explanations for this:
 This is an issue that has generated much debate over the years about the nature of Uralic expansions, who the Hungarians really were, and how the Hungarian language came to be spoken in the heart of Europe.
But I never understood what the fuss was about, because based on historical sources alone it seemed rather obvious that Hungarian was introduced into the Carpathian Basin during the Middle Ages by a relatively small number of invaders from the east, probably from somewhere around the Ural Mountains, who imposed it on local Indo-European-speaking populations.
As far as I can remember, this has always been the academic consensus, and the results from one of the first ancient DNA studies of human remains soundly corroborated it. Back in 2008, Csányi et al. reported that two out of four skeletons from elite Hungarian conqueror graves dating to the 10th century carried the Tat C allele, which meant that they belonged to Y-haplogroup N (see here).
We've since had to wait over a decade to get a more comprehensive look at the Y-chromosome haplogroups of medieval Hungarians. The most useful effort to date, a manuscript courtesy of Neparáczki et al., was posted this week at bioRxiv (see here).
The results in the preprint suggest a much more complex picture than simply a migration of an obviously Uralic-speaking population rich in Y-haplogroup N into the medieval Carpathian Basin. But they do confirm the presence of N in Hungarian conqueror elites, and, in fact, of very specific subclades of N that link them to the present-day speakers of Uralic languages from around the Ural Mountains. Here are some pertinent quotes from the prepint:
This is an issue that has generated much debate over the years about the nature of Uralic expansions, who the Hungarians really were, and how the Hungarian language came to be spoken in the heart of Europe.
But I never understood what the fuss was about, because based on historical sources alone it seemed rather obvious that Hungarian was introduced into the Carpathian Basin during the Middle Ages by a relatively small number of invaders from the east, probably from somewhere around the Ural Mountains, who imposed it on local Indo-European-speaking populations.
As far as I can remember, this has always been the academic consensus, and the results from one of the first ancient DNA studies of human remains soundly corroborated it. Back in 2008, Csányi et al. reported that two out of four skeletons from elite Hungarian conqueror graves dating to the 10th century carried the Tat C allele, which meant that they belonged to Y-haplogroup N (see here).
We've since had to wait over a decade to get a more comprehensive look at the Y-chromosome haplogroups of medieval Hungarians. The most useful effort to date, a manuscript courtesy of Neparáczki et al., was posted this week at bioRxiv (see here).
The results in the preprint suggest a much more complex picture than simply a migration of an obviously Uralic-speaking population rich in Y-haplogroup N into the medieval Carpathian Basin. But they do confirm the presence of N in Hungarian conqueror elites, and, in fact, of very specific subclades of N that link them to the present-day speakers of Uralic languages from around the Ural Mountains. Here are some pertinent quotes from the prepint:
- the speakers of Proto-Uralic were rich in N because they lived in an area, probably somewhere around the Ural Mountains, where it was common, and they spread it with them as they expanded from their homeland - Uralic languages often came to be spoken in areas of North Eurasia where N was already found at moderate to high frequenciesThe major exception to this rule are Hungarians, whose language belongs to the Ugric branch of Uralic. Their frequency of N is close to zero and they don't differ much in terms of overall genetic structure from their Indo-European-speaking neighbors in East Central Europe.

Three Conqueror samples belonged to Hg N1a1a1a1a2-Z1936, the Finno-Permic N1a branch, being most frequent among northeastern European Saami, Finns, Karelians, as well as Komis, Volga Tatars and Bashkirs of the Volga-Ural region. Nevertheless this Hg is also present with lower frequency among Karanogays, Siberian Nenets, Khantys, Mansis, Dolgans, Nganasans, and Siberian Tatars 23. ... It is generally accepted that the Hungarian language was brought to the Carpathian Basin by the Conquerors. Uralic speaking populations are characterized by a high frequency of Y-Hg N, which have often been interpreted as a genetic signal of shared ancestry. Indeed, recently a distinct shared ancestry component of likely Siberian origin was identified at the genomic level in these populations, modern Hungarians being a puzzling exception 36. The Conqueror elite had a significant proportion of N Hgs, 7% of them carrying N1a1a1a1a4-M2118 and 10% N1a1a1a1a2-Z1936, both of which are present in Ugric speaking Khantys and Mansis 23. ... Population genetic data rather position the Conqueror elite among Turkic groups, Bashkirs and Volga Tatars, in agreement with contemporary historical accounts which denominated the Conquerors as “Turks” 38. This does not exclude the possibility that the Hungarian language could also have been present in the obviously very heterogeneous, probably multiethnic Conqueror tribal alliance.Indeed, a large proportion of the 44 males from elite Hun, Avar and Hungarian Conqueror burials analyzed in the study belonged to Y-haplogroups that can't be plausibly associated with the earliest Uralic speakers, but rather with those of various Indo-European languages, such as I1 and R1b-U106 (these are Germanic-specific markers), I2a-L621 and R1a-CTS1211 (obviously Slavic) and R1a-Z2124 (largely Eastern Iranian). If most of these results aren't due to contamination, then it's likely that both the early Hungarian commoners and elites were, by and large, derived from Indo-European-speaking populations. No wonder then, that present-day Hungarians are basically indistinguishable genetically from their Indo-European-speaking neighbors and, like them, show hardly any Y-haplogroup N. See also... Hungarian Conquerors were rich in Y-haplogroup N (Fóthi et al. 2020) More on the association between Uralic expansions and Y-haplogroup N Ancient DNA confirms the link between Y-haplogroup N and Uralic expansions
Monday, December 3, 2018
On the trail of the Proto-Uralic speakers (work in progress)
Historical linguists have long posited that Fennoscandia was a busy contact zone between early Germanic and Uralic languages. The first ancient DNA samples from what is now Finland have corroborated their inferences, by showing that during the Iron Age the western part of the country was inhabited by a genetically heterogeneous population closely related to both the Uralic-speaking Saami and Germanic-speaking southern Scandinavians.
The samples were sequenced and analyzed by two different teams of researches, and their findings published recently in Lamnidis et al. and Sikora et al. (see here and here, respectively).
This is how most of these ancients, whose remains were excavated from the Levanluhta burial site dated to 300–800 CE, behave in a Principal Component Analysis (PCA) based on my Global25 data. Levanluhta_IA are the Saami-related samples, while Levanluhta_IA_o is an Scandinavian-like outlier. Baltic_IA is an Iron Age individual from what is now Lithuania from the recent Damgaard et al. paper (see here). Note the accuracy of the Global25 data in pinpointing their genetic affinities and also the trajectory of the Levanluhta_IA cluster, which seems to be "pulling" towards Levanluhta_IA_o.
 The Saami and Levanluhta_IA are clear outliers from the main Northern European cluster. There are two reasons for this: excess East Asian/Siberian-related ancestry and Saami-specific genetic drift. However, this eastern admixture and genetic drift are shared in varying degrees by other North European populations, especially those that also speak Uralic languages, and this is why they appear to be "pulling" towards the Saami/Levanluhta_IA clusters in my PCA. Thus, what this suggests is that the expansion of Uralic languages across Northeastern Europe was intimately linked with the spread of Siberian-related ancestry into the region.
This idea has been around for a long time and is now becoming even more widely accepted (see here). However, Lamnidis et al. also featured samples from a likely pre-Uralic (1523±87 calBCE) burial site at Bolshoy Oleni Ostrov in the Kola Peninsula, present-day northern Russia, and, perhaps surprisingly, found that they showed even more Siberian-related ancestry than Levanluhta_IA. So what's going on?
I'm confident that this discrepancy can be explained by multiple waves of migrations from the east into Northeastern Europe, possibly before, during and after the time of the people buried at Bolshoy Oleni Ostrov, by pre-Uralic, para-Uralic and/or Proto-Uralic-speaking populations.
Consider the following qpAdm output, in which Levanluhta_IA is just barely modeled successfully as a two-way mixture between Levanluhta_IA_o and Bolshoy_Oleni_Ostrov. The statistical fit improves significantly with the addition of Glazkovo_EBA as a third mixture source. This is an ancient population from near Lake Baikal dated to 4597-3726 BC from the aforementioned Damgaard et al. paper.
The Saami and Levanluhta_IA are clear outliers from the main Northern European cluster. There are two reasons for this: excess East Asian/Siberian-related ancestry and Saami-specific genetic drift. However, this eastern admixture and genetic drift are shared in varying degrees by other North European populations, especially those that also speak Uralic languages, and this is why they appear to be "pulling" towards the Saami/Levanluhta_IA clusters in my PCA. Thus, what this suggests is that the expansion of Uralic languages across Northeastern Europe was intimately linked with the spread of Siberian-related ancestry into the region.
This idea has been around for a long time and is now becoming even more widely accepted (see here). However, Lamnidis et al. also featured samples from a likely pre-Uralic (1523±87 calBCE) burial site at Bolshoy Oleni Ostrov in the Kola Peninsula, present-day northern Russia, and, perhaps surprisingly, found that they showed even more Siberian-related ancestry than Levanluhta_IA. So what's going on?
I'm confident that this discrepancy can be explained by multiple waves of migrations from the east into Northeastern Europe, possibly before, during and after the time of the people buried at Bolshoy Oleni Ostrov, by pre-Uralic, para-Uralic and/or Proto-Uralic-speaking populations.
Consider the following qpAdm output, in which Levanluhta_IA is just barely modeled successfully as a two-way mixture between Levanluhta_IA_o and Bolshoy_Oleni_Ostrov. The statistical fit improves significantly with the addition of Glazkovo_EBA as a third mixture source. This is an ancient population from near Lake Baikal dated to 4597-3726 BC from the aforementioned Damgaard et al. paper.

Levanluhta_IA Bolshoy_Oleni_Ostrov 0.468±0.036 Levanluhta_IA_o 0.532±0.036 chisq 19.129 tail prob 0.0854706 Full output Levanluhta_IA Bolshoy_Oleni_Ostrov 0.241±0.092 Glazkovo_EBA 0.162±0.059 Levanluhta_IA_o 0.597±0.046 chisq 7.756 tail prob 0.734966 Full outputFor the sake of being complete, I also tested whether Levanluhta_IA_o could be substituted by other similar ancient samples from the neighborhood, including those associated with the Battle-Axe and Corded Ware cultures. There's not much to report; qpAdm returned poor statistical fits and/or implausible ancestry proportions (for the full output from my runs, see here). Baltic_IA did produce a statistically sound model, but with excess Glazkovo_EBA-related ancestry. I also had to drop Bolshoy_Oleni_Ostrov from the analysis to make things work, which suggests to me that the result shouldn't be taken too literally.
Levanluhta_IA Baltic_IA 0.677±0.034 Glazkovo_EBA 0.323±0.034 chisq 8.547 tail prob 0.741095 Full outputSo as far as I can see, the western ancestry in Levanluhta_IA is likely to be mostly of Germanic origin, and thus Indo-European, meaning that it's logical to look east, perhaps far to the east, for the source of its Uralic ancestry. This might seem like a complicated and uncertain task, considering that Levanluhta_IA could well be at least a thousand years younger than the first entry of Uralic speakers into Fennoscandia. However, take a look what happens when I substitute Glazkovo_EBA with a variety of Uralic-speaking populations from around the Ural Mountains, which is where the Proto-Uralic homeland is generally considered to have been located.
Levanluhta_IA Bolshoy_Oleni_Ostrov 0.210±0.091 Khanty 0.283±0.090 Levanluhta_IA_o 0.507±0.035 chisq 7.007 tail prob 0.798532 Full output Levanluhta_IA Bolshoy_Oleni_Ostrov 0.193±0.098 Levanluhta_IA_o 0.495±0.035 Mansi 0.312±0.100 chisq 7.884 tail prob 0.7237 Full output Levanluhta_IA Bolshoy_Oleni_Ostrov 0.300±0.065 Levanluhta_IA_o 0.337±0.072 Mari 0.363±0.121 chisq 8.393 tail prob 0.677705 Full output Levanluhta_IA Bolshoy_Oleni_Ostrov 0.238±0.084 Levanluhta_IA_o 0.553±0.036 Nenets 0.209±0.067 chisq 7.210 tail prob 0.78181 Full output Levanluhta_IA Bolshoy_Oleni_Ostrov 0.302±0.069 Levanluhta_IA_o 0.324±0.081 Udmurt 0.373±0.135 chisq 9.195 tail prob 0.60393 Full outputAll of these models look great, and easily rival the best model with Glazkovo_EBA. Moreover, they make good sense in terms of linguistics. The only problem is that they're anachronistic, because the Uralic-speaking reference populations are younger than Levanluhta_IA. So I can't be certain that they reflect reality without corroboration from ancient DNA. It might turn out, for instance, that a Glazkovo_EBA-like population was already present somewhere deep in Europe before or during the time of Bolshoy_Oleni_Ostrov, while no such population existed around the Ural Mountains until the time of Levanluhta_IA. By the way, it might be important to note that the present-day Finnish samples in my dataset can't be modeled as a mixture between Levanluhta_IA and Levanluhta_IA_o. But they can be modeled as a mixture between Baltic_IA and Levanluhta_IA. I don't know which part of Finland they're from exactly; probably all over the place, so it'd be useful to test regional Finnish populations to see how they behave in such models. Of course, Finns aren't Saamic speakers, they're Finnic speakers, and they're probably the result of a more recent Uralic expansion into Fennoscandia than the one that gave rise to the Saami.
Finnish Baltic_IA 0.671±0.076 Levanluhta_IA 0.329±0.076 chisq 14.114 tail prob 0.293508 Full outputDamgaard et al. didn't report the Y-haplogroup for Baltic_IA, but the word round the campfire is that this individual belonged to N1c, which is today the most common Y-haplogroup among Uralic speakers. Obviously, we need a lot more ancient DNA to sort all of this out, but things are already looking pretty much as expected. Stay tuned for new posts in this series following the publication of more ancient DNA relevant to this fascinating topic. See also... How did Y-haplogroup N1c get to Bolshoy Oleni Ostrov? The Uralic cline in the Global25 Late PIE ground zero now obvious; location of PIE homeland still uncertain, but...
Subscribe to:
Posts (Atom)